Claim Construction Tutorial
by Philip Greenspun and John Morgan
Site Home : Software : How to Write a Claim Construction Tutorial : One Example
The objectives of this tutorial are (1) to provide background and
context of "web-based database application" technology, (2) to help the
reader understand the challenges faced by computer programmers
building Web applications, especially those backed by relational
database management systems, in the 1990s and, (3) to explain how the
system described in U.S. Patent 6,832,226 would automate some of the
tasks conventionally performed by human programmers.
Topics addressed in this tutorial include the following:
(Individual sections may be accessed by clicking the subtitles above,
or scroll down to read the entire document in sequence. This document
best viewed in a Web browser so that the hyperlinks to additional
information are functional. To adjust font size, use browser controls such as "View ->
Text Size" or hold down control key and type "+" (ctrl-+).)
I. What is a database?
A database is an organized collection of information. A computer
program that assists programmers with common challenges regarding
creating, updating, and querying a database is a database
management system (DBMS). The most popular type of DBMS is the
relational DBMS or "RDBMS", the best conceptual model for which is "a
big spreadsheet that several people can update simultaneously."
Information within an RDBMS is stored in tables. Communication with
the RDBMS is via the Structured Query Language (SQL), which includes
statements such as CREATE TABLE, INSERT (add a row), UPDATE (change a
data item within a table), DELETE (remove a row), and SELECT (return a
report). The "SQL schema" or "data model" is a collection of CREATE
TABLE statements that prepares the RDBMS to accept data items.
For example, suppose that a Web site developer wished to record
subscribers to an email newsletter. He or she would create a new
table called mailing_list with two
columns (also sometimes called "fields"), email
and name, both text strings that can be up to 100
characters in length ("varchar(100)"):
create table mailing_list (
email varchar(100),
name varchar(100)
);
After a series of INSERT commands, the contents of this table may be
viewed in a spreadsheet format, e.g.,
| name | email |
|---|
| Philip Greenspun | philg@mit.edu |
| Bill Gates | billg@microsoft.com |
| Scott Adams | scottadams@aol.com |
by typing a SELECT statement such as
select name, email from mailing_list
Each row in the table is also referred to as a
record. Note that, unlike with a desktop spreadsheet
application, every data item in the same column, e.g.,
email, must be of the same data type (in this case a
character string).
II. What is a database application?
A database application is a computer program whose
primary purpose is entering information into and retrieving
information from a computer-managed database. Some of the earliest
database applications were accounting systems and airline reservation
systems such as SABRE,
developed between 1957 and 1960 by IBM and American Airlines.
Users interacted with early database applications, such as SABRE, by
typing at a terminal connected directly to a mainframe computer
running the database management system. The IBM 3270 terminal,
introduced in 1972, was a very commonly used device. The terminal had
no ability to process information, but merely displayed characters or
"screens" sent from the mainframe.
Software development for an early database application was simply
software development for the mainframe computer, which executed all of
the program code centrally. Software was developed in assembly
language, a "second-generation language", or one of the
"third-generation languages" developed in the late 1950s and early
1960s, e.g., COBOL, Fortran, or PL/I. Whatever conventional
programming language was used, there may have been embedded database
commands in a specialized query language.
III. Client/server database applications
A client/server database application is a system in which the programs
to organize data and interact with users have been split up among a
central server and distributed personal computers. With the
development of the inexpensive personal computer in the 1980s, it did
not make sense to have a central mainframe do all of the
work. Programmers realized that substantial performance and
interactivity improvements could be achieved by distributing some of
the logic, especially software related to user interface, to machines
on users' desktops. The central computer (server) was
retained, but it ran only the database management system (DBMS). The
personal computers on users' desktops (clients) ran the
software that displayed menus and reports, drew graphs and charts, and
sent queries and transactions to the DBMS. Instead of screens and
keystrokes being communicated from the central computer to the
desktop, the desktop PC would send queries to the DBMS and receive
results back in exchange. As the rise of the desktop PC coincided with
the rise of the relational database management system (RDBMS),
conceived in 1970 and introduced commercially in 1979 by Oracle
Corporation, the most common language flowing between clients and
servers was SQL.
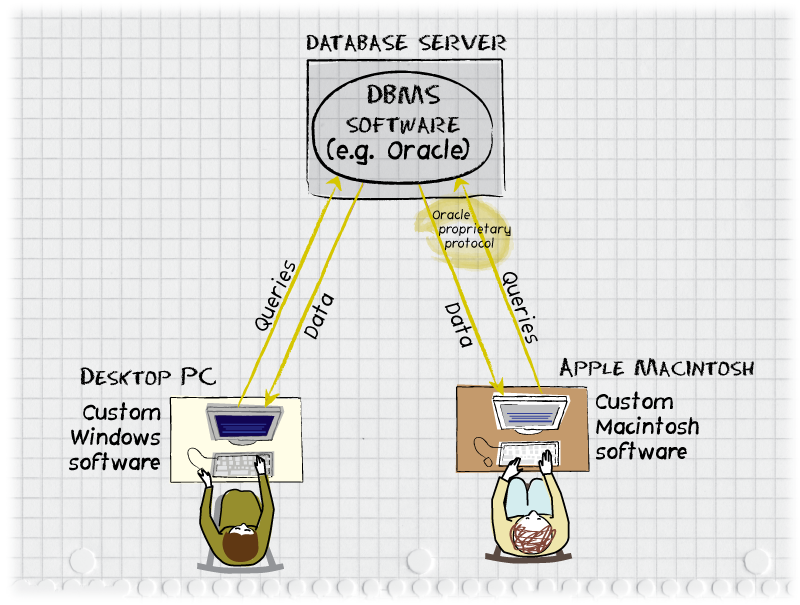
Figure 1: A typical corporate database application, circa 1989. A
central Oracle database server communicates with a user on a Windows
PC and a user on an Apple Macintosh. Queries, typically in the
Structured Query Language (SQL) are sent from the desktop computers
via a proprietary protocol specific to the particular RDBMS software
being used. Due to the differences in the desktop operating systems,
separate versions of the client software must be developed. Note that
oftentimes all three of the computers depicted would be on a
local-area network, e.g., within an office building, but the
architecture and software worked equally well across internets or the
public Internet.
IV. What is a Web application?
A "Web application" is a server-based computer program that can be
used by a user sitting in front of a standard Web browser, such as
Microsoft Internet Explorer, Firefox, or Google Chrome. Examples of
Web applications include wikipedia.org, nytimes.com, facebook.com,
and youtube.com. The advantage of the Web, compared to client/server, is
that no specialized software need be installed on the end-user's
computer. The same personal computer or mobile phone and the same Web
browser can be used to read a news article from nytimes.com, order a
book from amazon.com, or calculate the cost of a new car using Google
Spreadsheets. A classical Web application is very similar to an old
mainframe application. All computation is performed on the central
computer in response to a request for a URL
(e.g., "http://www.nytimes.com/pages/business/index.html
requests the file "index.html" located in the "/pages/business/"
directory on the nytimes.com server)
and only information necessary to paint a "screen" is sent to the
device on the user's desktop via the Hypertext Transfer Protocol
(HTTP). Thanks to 30 years of progress in microelectronics, the
desktop device can display color graphics rather than simply green
characters, but the software ideas are very similar.
Rather than the IBM 3270 terminal protocol, the specifications for the
screen or "page" to be displayed are sent in Hypertext Markup
Language (HTML), which is a specification or format for a document
(analogous to the format in which Microsoft Word, for example, might
save a file to disk). The structured data in HTML is distinct from a
programming
language, which generally either express a step-by-step algorithm
for a computer to follow or specify a computation to be performed.
A. Static HTML Pages
Some early Web sites, e.g., online manuals, were simply static
collections of HTML documents and digital images. The server did no
computation other than processing the request to see which file was
being requested and then delivering the contents of the file via
HTTP. These were informally referred to as "static sites". Every user
who requested a file with a particular name would be served exactly
the same contents, regardless of the identity of the user, the time of
day, or what files had been previously requested by that user.
Here is an example of a one-sentence .html page:
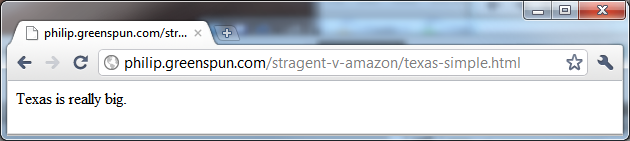
The source HTML behind this page is a file whose entire contents is
the character string "Texas is really big." In other words, a
plain-text string of characters can be rendered by a Web browser as an
HTML document. Every word appears in the default font and face.
Suppose the author wishes to emphasize the word
"really":
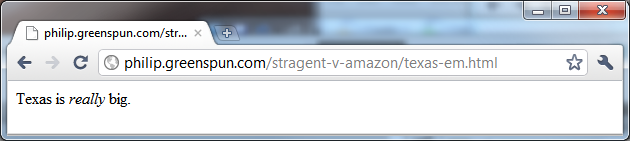
This is accomplished by surrounding the word with an "emphasize" tag:
"Texas is <em>really</em> big." The Google Chrome browser,
used to create the above screen shot, after reading the EM tag,
elected to display the word "really" in italics. That's the
markup part of HTML. A typical HTML document looks more
like the following:
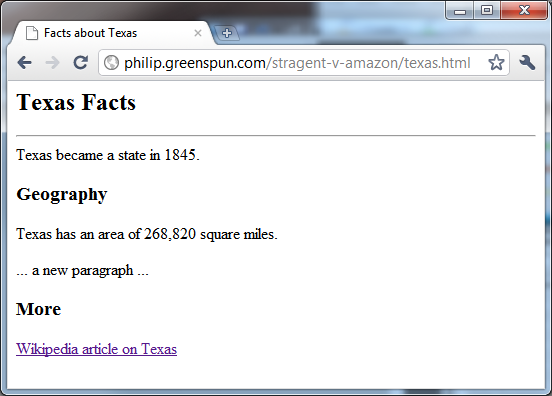
Here's the HTML behind the preceding page:
<html>
<head>
<title>Facts about Texas</title>
</head>
<body bgcolor=white text=black>
<h2>Texas Facts</h2>
<hr>
Texas became a state in 1845.
<h3>Geography</h3>
Texas has an area of 268,820 square miles.
<p>
... a new paragraph ...
<h3>More</h3>
<a href="http://en.wikipedia.org/wiki/Texas">Wikipedia article on Texas</a>
</body>
</html>
After the BODY, which represents the start of the document to be
displayed, "Texas Facts" is marked up as an H2 headline. The HTML then
specifies a horizontal rule (HR) across the page, includes a sentence
about Texas's statehood, and then marks up the word "Geography" as a
smaller H3 headline. At the bottom is a link to Wikipedia using the A
tag. This is the hypertext part of HTML. As noted above, HTML
is structured data representing a document. It is not a programming
language and lacks the most basic capabilities for programming, e.g.,
it is not possible to instruct a computer to add two numbers via
HTML. There is no "ADD" tag.
B. Computer programs that generate HTML pages
Via the Common
Gateway Interface ("CGI"; developed in 1993), it became
conventional to write short computer programs that would run on the
server when a Web address was requested by a browser. These programs
could be written in any programming language and the only restriction
on their behavior was that their eventual output conformed to a
standard Web server response. These programs are typically short and
simple and referred to as "page scripts". Here's an example of a page
generated by a computer program (in the Perl programming language):
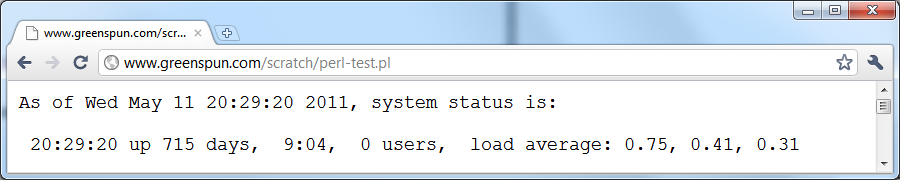
Here's the Perl program that generated the preceding page:
#!/usr/bin/perl
# the (above) first line says where to find the interpreter
# for the rest of the program
# any time we print, the output goes to the user's browser
print "Content-type: text/plain\n\n";
# now we have printed a header (plus two newlines) indicating that the
# document will be plain test; whatever else we write to standard
# output will show up on the user's screen
# Get the current time as a string.
$current_time = localtime();
# Run a program to get the system status.
$system_status = `/usr/bin/uptime`;
print "As of $current_time, system status is:\n\n$system_status\n";
Note that the output displayed by the browser is a combination of
static text, e.g., "As of" and "system status is:", and information
obtained or calculated by the running Perl program. All of this is
happening on the server; all that the browser knows is that it
received a stream of plain text characters (based on the "text/plain"
Content-type sent by the first line of code in the Perl program).
V. What is a Web-based database application?
The '226 patent's title includes the phrase "Web-based Database
Application". What does this mean? It is simply a combination of the
systems described above, i.e., "a computer program that can be used by
a user sitting in front of a standard Web browser whose primary
purpose is entering information into and retrieving information from a
computer-managed database". No additional software needs to be
installed by end-users. The computer programs on the server, however,
are modified so that they rely on a database management system (DBMS)
for storing and retrieval of information. The user requests pages by
URL, as before, and in response the server will run computer programs
(page scripts) that will generally access the DBMS and then merge the
results with a template in order to build up a complete HTML page to
return.
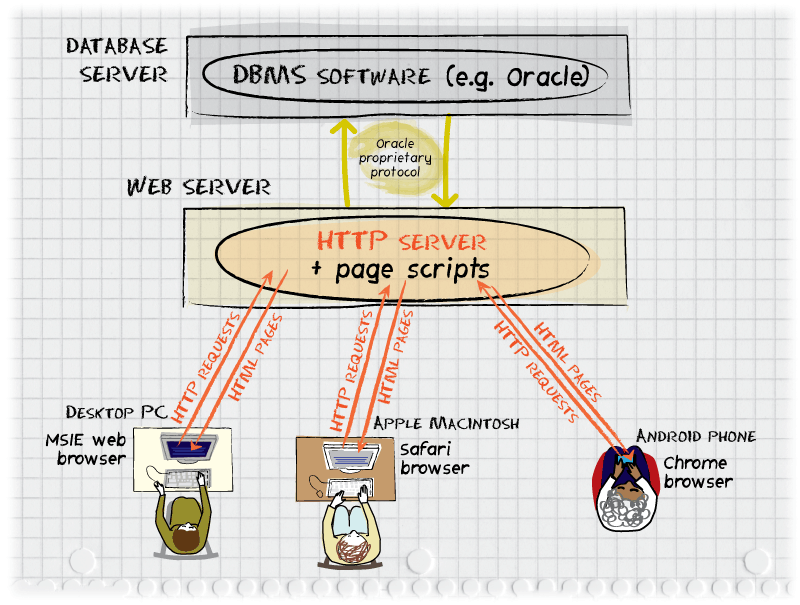
Figure 2: A database-backed Web site or "Web-based Database
Application". A request is made by a browser on a standard personal
computer or a smartphone and is sent via HTTP to the Web server. The
Web server runs a small computer program (page script) to handle the
request. The page script will send a SQL query to the database
management system and, using those data items, build a complete HTML
page to return to the requesting browser. Note that the software on
the users' computers and mobile phones need not be customized in any
way for the application or the DBMS used. Unlike with the
client/server architecture, all programming here can be done on the
central server. As with the client/server architecture, the computers
in this drawing might all be in the same building and connected via a
local-area network or the end-users might be on different continents
connecting via the public Internet.
The structure of one of the page scripts shown in Figure 2 is best
explained by example. The flow chart below uses an example of a bank
customer logging in to view the most recent transactions to his or her
account. After typing in a username and password, the customer clicks
on a "view transactions" link. This causes the browser to request the
link "/transactions" from the Web server, which will run a page script
(short computer program) in response. The page script will connect to
the RDBMS, query the transactions table, and then merge
the data items received back from the database with some fixed HTML (a
"template") in order to build a complete HTML page to return to the
customer. The final HTML page as viewed by the customer will contain
some boilerplate content from the HTML template, but also a list of
recent transactions that have been queried from the RDBMS.
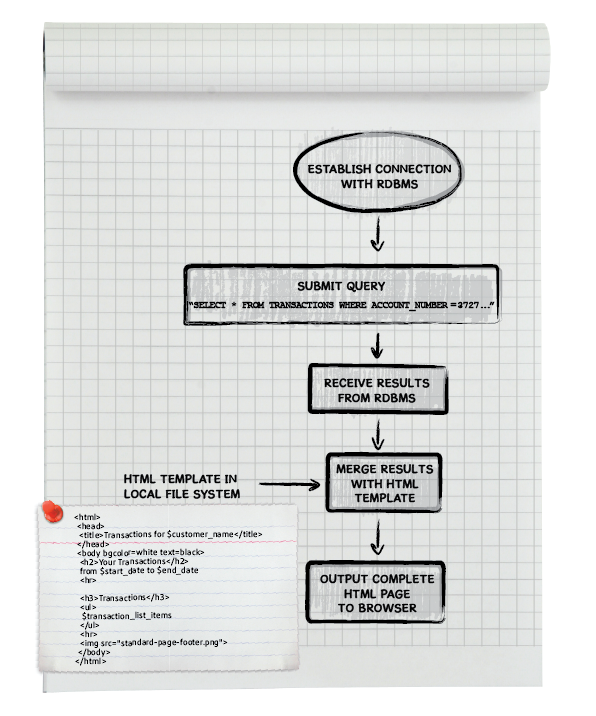
Figure 3: Flow chart for a page script that shows a bank customer's
most recent transactions. The short computer program logs into the
RDBMS, sends it a SQL query for rows from the
transactions table that match the customer's account
number. Once the results (data items) are received, they are merged
with an HTML template that the program reads from the server's file
system. The complete HTML page is sent to the customer's browser. See
this link for some example
source code.
VI. How were Web-based database applications built in the 1990s?
For a Web-based database application being built from scratch, the
classical development process included (and still includes, as of
2011) the following steps:
- human programmer talks to business manager to find out what is needed
- human programmer develops SQL schema or "data model" (tables and columns)
- if existing data needs to be incorporated, copy those data from text or binary files into the RDBMS tables
- human programmer writes application pages (computer programs) that query database and return HTML pages to user
- if business requirements change, human programmer alters SQL schema by adding tables or columns
- human programmer modifies (edits with a text editor) the
application pages (computer programs) to update and query the added
tables and columns
Note that Steps 5 and 6 will be repeated throughout the life of the application.
A. Steps 1 and 2 Example
Suppose that the programmer learned from the business manager that a
goal was to add a feature to the company's Web site whereby visitors
could sign up to receive email notifications of new products. The
result might be the development of the following SQL schema:
create table mailing_list (
email varchar(100) not null primary key,
name varchar(100)
);
This is a SQL command that tells the RDBMS to make space for a new
table called mailing_list. This table will have two
columns, both variable length character strings.
This single table can be considered the application
database as it holds all of the data to be processed by the
application.
A critical part of almost any SQL schema is a set of integrity
constraints. These are restrictions on the data that will be enforced
by the database management system. Without integrity constraints, a
company's valuable data may gradually become inconsistent as a
consequence of small mistakes in computer programs that use the
database. In the case of this example one-table data model, the
programmer has added two integrity constraints on the
email column: not null primary key. The
not null constraint will prevent any program from
inserting a row where name is specified but
email is not. The manager said that the company did not
want to require a full name, but needed the email address in order to
send out the announcements. The primary key constraint
tells the database that this column's value can be used to uniquely
identify a row. That means the system will reject an attempt to insert
a row with the same e-mail address as an existing row and therefore
prevent customers from receiving duplicate emails. Note that a
real-world SQL schema could have additional constraints, e.g., that
submitted email addresses match a pattern that included an "@" in the
middle.
B. Step 3: Copy data into the RDBMS tables
If the company already has a spreadsheet containing customer names and
email addresses, the next step might be to copy those data
items into the new SQL table:
| Philip Greenspun | philg@mit.edu |
| Bill Gates | billg@microsoft.com |
| Scott Adams | scottadams@aol.com |
Note that in this example there is some information about the
structure and organization of the information in the spreadsheet. We
have data items that are pre-divided into rows and columns. This makes
it a much simpler task for a human to write a program to transfer
these data items into the corresponding columns of the
mailing_list table.
C. Step 4: Write application pages (computer programs)
Finally the human programmer will write the application pages (page
scripts) that make it possible for end-users to interact with the
contents of the database. At least the following pages are likely to
be required:
- http://thecompany.com/signup (a form where a public user can submit his or her name and email address)
- http://thecompany.com/signup-2 (a computer program that processes a form submission and adds one row to the
mailing_list table)
- http://thecompany.com/admin/view-mailing-list (a page for a manager to see who has signed up and click on any entry to edit)
- http://thecompany.com/admin/edit-mailing-list-entry (a form that defaults to the current name and email address for one entry, but allows an administrator to change one or both data items)
- http://thecompany.com/admin/update-mailing-list-entry (a computer program that runs in response to a submission from the edit-mailing-list-entry form)
- http://thecompany.com/admin/send-to-mailing-list (a form for typing in an announcement)
- http://thecompany.com/admin/send-to-mailing-list-2 (a computer program that will send a submitted announcement to each email address in the
mailing_list table)
Note that the structure and function of many of these pages are
predictable and flow more or less deterministically from the SQL table
definition. For example, the signup page will offer "email" and "name"
fields. If it offered a "phone number" field there would be no place
to store the entered data. Due to the predictability and repetitive
nature of writing the software to run in response to requests for
these URLs, a programmer even in the 1990s might rely on a variety of
automated and semi-automated tools, sometimes called "wizards", to
help in developing at least the skeletons of these pages. Typically
pages produced by a wizard would require editing by a
human programmer in order to create a functional and useful application.
D. Steps 5 and 6: Change the data model and application pages
Suppose that a manager asks "Wouldn't it be nice if we could also ask
folks for a phone number?" The programmer could add a column for up
to 20 characters (allows country codes and symbols such as "+" and
parentheses):
alter table mailing_list add (phone_number varchar(20));
or the programmer could add an additional table so that home, work,
and mobile numbers could be stored for each subscriber:
create table phone_numbers (
email varchar(100) not null references mailing_list(email),
number_type varchar(15) check (number_type in ('work','home','cell','beeper')),
phone_number varchar(20) not null
);
Which application pages must now be changed?
- http://thecompany.com/signup (add one or more telephone number entry boxes)
- http://thecompany.com/signup-2 (change SQL INSERT transaction)
- http://thecompany.com/admin/view-mailing-list (change SQL query; add at least one column to display a phone number)
- http://thecompany.com/admin/edit-mailing-list-entry (add capability of editing phone number)
- http://thecompany.com/admin/update-mailing-list-entry (change SQL UPDATE statement to update the phone number as well)
- http://thecompany.com/admin/send-to-mailing-list
- http://thecompany.com/admin/send-to-mailing-list-2
In this example, as a consequence of a very simple change to the data
model (adding the ability to record phone numbers), 5 out of the 7
computer programs (in bold face above) that constitute the application
must be changed. Every change is conventionally done by a human
programmer opening a file in a text editor and typing, which creates a
risk of an error being introduced into what had been a perfectly
functioning application.
VII. Approaches to automatic generation of application code in the
1990s
Simultaneously with the rise of the RDBMS and the 1980s client/server
world, enterprises continued to ask "Can we cut the cost and time
required to develop database applications?" Expert programmers have
always been scarce and do not necessarily have the best understanding
of business requirements. Furthermore, it was observed that once the
SQL tables and columns had been defined, portions of the likely
structure of the application could be sketched out by a computer
program. If there was, for example, a table called CUSTOMERS with a
column CUSTOMER_NAME, there would need to be a form where a new
customer could be entered, including a field for CUSTOMER_NAME, and
also the application would need to include a form for editing the value
of that field, in the event that the customer was acquired or
otherwise changed its business name.
Examples of tools that enabled people to develop "screens" or "forms"
without using a standard programming language included Oracle Forms, dating back
to the early 1980s, and PowerBuilder, a popular tool for building
graphical user interfaces (GUIs) introduced in 1991. Generally these
products were called "Fourth Generation Languages" (4GL), to
distinguish them from "third-generation languages" such as COBOL and
Fortran. A more or less complete list of such languages and tools may
be found at http://en.wikipedia.org/wiki/4GL. Because
a standard relational database management system can be queried
programmatically to determine the names and structure of user-defined
tables, an early standard feature of these 4GL tools was the automatic
generation of basic data entry or retrieval forms and pages. E.g., if
a table had 10 columns and the 4GL programmer started to build a data
entry form, the 4GL tool would offer a menu asking which of the 10
columns should be included in the new form and then generate a
prototype. The human programmer could edit this automatically
generated code by, for example, adjusting the order in which fields
were presented or changing the length of an input box. Various
Microsoft tools, including Visual Studio (introduced in 1995, but
incorporating older software), included similar features and
popularized the term "wizard" to describe software that led a human
through a series of menus and eventually created a computer
program based on the choices made.
One advantage claimed for these 4GL tools was
"platform-independence". The PowerBuilder or Oracle Forms programmer,
for example, did not need to produce separate versions for Microsoft
Windows and Apple Macintosh computers. The tool developer, e.g.,
Oracle or Sybase, would write some operating system-specific code and
then the customer's 4GL program would execute on top of
that. Companies that installed a mid- or late-1990s release of the 4GL
tools would have an additional option of running their 4GL application
on a Web server. End-users would then interact with the application
through a standard Web browser making HTTP requests and receiving HTML
pages in return. Using this method, some companies were able to make
internal database applications work as Web applications without
writing any new software.
A. automatic code generation without using a client/server tool
PowerBuilder and similar systems from the client/server era saved a
lot of programmer time, but many of their features, e.g., the ability
to generate programs that would run on a desktop computer, weren't
necessary in the Web era. In 1999 a small group of programmers
building Sharenet, a knowledge sharing system for Siemens, made an
independent effort to reduce development time, revision time, and
errors introduced during revisions. The programmers built a complete
machine-readable specification of the application and then wrote a
program-to-write-the-program. The program-to-write-the-program read
the specification of what needed to be stored and how it was to be
presented to end-users and generated all of the computer programs (SQL
schema plus page scripts) for the application. When Siemens requested
substantial changes to the application following a test of the
prototype, the changes were made to the machine-readable specification
and the entire application was quickly regenerated. This process is
described in "Metadata (and
Automatic Code Generation)", a chapter within the MIT Press
textbook Software Engineering for Internet
Applications.
A more common approach taken by 1990s programmers who were given the
task of reducing the amount of custom software development for
individual applications was building computer programs whose behavior
varied depending on information stored in the DBMS. For example, Viaweb, which became
Yahoo! Store in 1998 and still exists under Yahoo! Small Business,
offered multiple online stores, each for a different merchant, but
served by a common set of computer programs and database. The
programmers could predict that nearly every merchant would want to
store, for each product, a name, a description, and a price. However,
a camera shop might want to record and display "Lens Mount" for most
of its products, reflecting whether a particular item was designed to
fit onto a Nikon or Canon camera, for example. Yahoo! Store allowed a
merchant to define a "custom field", which resulted in metadata (data
about data) being recorded in the database and the interface for that
particular merchant's customers to be updated to show Lens Mount. The
same metadata would result in the administrative pages for the online
store including options to set or update the lens mount field.
A later example of the "custom field" technique is photo.net's photo
sharing system, developed in the spring of 1999 as an MIT student
project (and still running today at http://photo.net/gallery/). More
information about the development of this system, including the SQL
schema that supports it, is available here.
VIII. Hardware and software required to host a Web-based database application
The software required to host a typical Web-based database application
includes the following:
- HTTP server program that interprets or executes page
scripts (small computer programs) that generate responses to
individual Web requests and sends the output of those programs back to
the browser
- a file system to store application pages, including
computer programs, and static content for the application, such as
photographs, videos, and digital audio files
- a database management system (DBMS) to store organized and
indexed tables of information
The HTTP server program processes requests from browsers and
delivers responses to those requests. A response could be the contents
of a file, a "not found" error message, or the output of running a
computer program. Popular examples of HTTP servers are Apache and
Microsoft Internet Information Server, and generally an efficient
means for running short computing programs in response to Web requests
(the old CGI standard is functional, but not efficient). Examples of
additional software that might be loaded into the HTTP server include
a PHP processor or Microsoft Active Server Pages.
The file system is a standard part of most operating systems
and allows named collections of information to be stored persistently,
e.g., on a hard disk drive, and then retrieved by name. The file
system on a server is no different than the file system on a desktop
computer. Furthermore, the file system on a separate physical machine
can typically be read from and written to just as easily as the local
file system. If a group of physical or virtual computers are
cooperating to deliver a Web application, they may share one file
system so that they can all load the same application pages and so
that information written by one computer can be read by another. In
that case, a separate computer, physical or virtual, would be
dedicated to running the file system and would be called the "file
server". A variety of cloud computing providers offer a file system
service; examples include Google Storage and Amazon S3. These free the
owners of the application from having to purchase and maintain server
hardware or worry about backing up information in a file system.
The database management system (DBMS) allows multiple
simultaneous updates to be handled in an orderly fashion and at the
same time as queries are responded to. Very commonly, the DBMS is a
performance bottleneck and therefore is often split off onto a
separate computer, physical or virtual. A "database server" requires a
combination of software and hardware (though the hardware could be
virtual). Examples of popular DBMS software include Microsoft SQL
Server, MySQL, and Oracle. Administering a DBMS can be challenging,
particularly because of the availability and reliability
required. Therefore some cloud computing services offer database
management systems, albeit with many fewer features than traditional
RDBMSes such as Oracle. Examples include the Google App Engine
Datastore and Amazon SimpleDB.
All of this software could run on any general-purpose computer running
a standard operating system such as Unix or Microsoft Windows. In the
early days of the Web, it was not uncommon for a programmer to host a
Web site on his or her desktop computer. The resulting site would be
accessible to others within a company (if the desktop machine were
connected to a local-area network) or Internet users around the world
(if the desktop machine were connected to the public Internet, a
common situation at universities). As Web sites grew in popularity, it
became common to use dedicated servers to respond to user
requests. Starting in the late 1990s, the virtual
machine IBM idea from the 1960s was resurrected. To achieve total
isolation between two Web applications, for example, each could run in
its own virtual machine on top of a single physical machine (i.e., a
physical computer). Initially this was done by the owners of physical
machines for their own purposes; today it is possible to rent
virtual machines from a number of different "cloud computing"
providers. A heavily used application, such as Facebook, will require
multiple computers (physical or virtual) to handle all of the
requests. (http://www.datacenterknowledge.com/the-facebook-data-center-faq-page-2/
quotes a Facebook employee saying that "When Facebook first began with
a small group of people using it and no photos or videos to display,
the entire service could run on a single server" and then notes that
"as of June 2010 the company was running at least 60,000 servers")
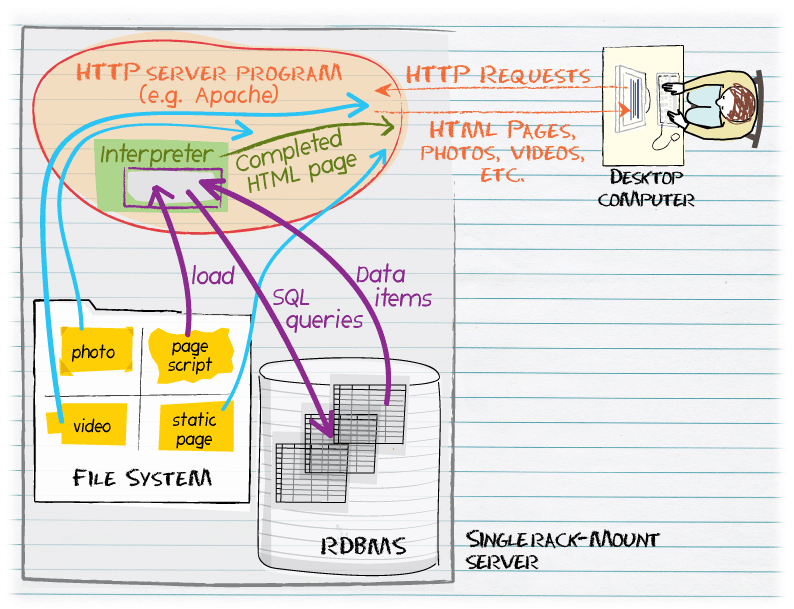
Figure 4: A single physical computer (usually a slender rack-mount
server) operates a Web-based database application. The computer runs
an RDBMS, where structured data are stored, and a conventional file
system, where static content is kept and also small computer programs
that run in response to Web requests. When a request for a
program-generated page is received, the HTTP server retrieves the
computer program from the file system, loads the program into an
interpreter, and starts the program running. The program, sometimes
called a "page script", will typically send a SQL query to the RDBMS
and receive data items back in response. The program merges these data
items from the RDBMS with static HTML elements and returns a complete
page to the desktop computer.
IX. U.S. Patent 6,832,226 (the "'226 Patent")
Going back to the six steps involved in a hand-authored Web-based database application:
- human programmer talks to business manager to find out what is needed
- human programmer develops SQL schema or "data model" (tables and columns)
- if existing data needs to be incorporated, copy those data from text or binary files into the SQL tables
- human programmer writes application pages that query database and return HTML pages to user
- if business requirements change, human programmer alters SQL schema by adding tables or columns
- human programmer modifies (edits with a text editor) the
application pages (computer programs) to update and query the added
tables and columns
The set of computer programs referred to by the '226 Patent would
eliminate most or all of this labor and all of the required technical
training. See Col. 1:39-41: "development of web-based database
applications without needing a programmer or web developer;" see also
Col. 1:44-46: "the ability of a user to change the look and feel of
the application pages without needing a programmer or web
developer".
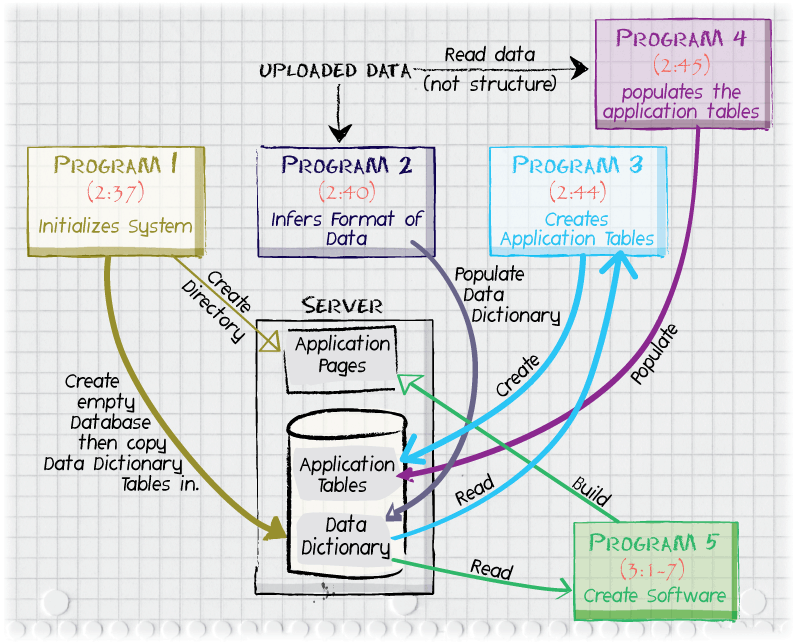
Figure 5: Five programs referred to in the '226 patent specification
(specific Column:Line citations within each box) automatically perform
all of the steps necessary to build a Web-based database
application. These five programs run in sequence and cooperate to
build up a set of computer programs (non-static application pages)
that connect to tables in a relational database management system,
which also stores the metadata ("data dictionary") used to create and
update the application. An important feature not shown in this
illustration is that of a sixth program that facilitates updating of
the data dictionary. After such updates are a made, Programs 3, 4, and
5 may run again in order to keep the application in sync with the data
metadata.
A. Step 1: human programmer talks to business manager to find out what
is needed; Step 2: human programmer develops SQL schema or "data model" (tables and columns)
These steps are performed automatically. Program 1 (Col. 2:37) creates an
electronic workspace for the project, a database that will eventually
hold the application tables and a file system directory that will
eventually hold page scripts ("application pages"). "Program 2",
referred to at 2:40-44 in the '226 patent, is described as being able
to infer the structure of the uploaded data and possibly infer the
objective of the proposed application by looking at the structure and
content of "uploaded electronic data". The Detailed Description
section of the patent (Col. 4:39-48) refers to Figure 3, a high level block
diagram of a data dictionary being updated by a computer
program. According to Col. 4:49, "the electronic information can be in many
forms, including PC-based databases (e.g., Microsoft's Access, FoxPro,
dBase, Paradox, etc.), spreadsheets, and text files". At 5:11, an
example of using "an Access MDB" is disclosed. Presumably this refers
to a file with a ".mdb" extension produced by the Microsoft Access
product. The format and structure of MDB files are proprietary to
Microsoft and have not been made public. The '226 patent does not
explain the structure of such a file, nor give any references to where
the structure might be documented.
1. Working with Microsoft MDB files
We searched for "microsoft MDB file format" and "parsing microsoft MDB
files" in the Association of Computing Machinery Digital Library, a
collection of more than 1.6 million books and academic journal
articles, but did not find anything relevant. A Google search
performed on May 8, 2011 uncovered Web sites from programmers who have
made some attempts to guess Microsoft's proprietary format. The most
comprehensive attempt seems to be the MDB Tools project: "a[n] effort
to document the MDB file format used in Microsoft's Access database
package, and to provide a set of tools and applications to make that
data available on other platforms." (http://mdbtools.sourceforge.net)
The mailing list archive for this project indicates that the code is
actively being used as of May 2011. The format of at least some MDB
files is implicit in the more than 15,500 lines of C source code, but
the principal author also wrote two documents summarizing what he had
learned: January 12, 2003
notes; March 4, 2004
notes. The highlights
from these files reveal that even by 2003 and 2004, the format used by
Microsoft Access in 1997 was not completely understood, e.g.,
"The first byte of each page seems to be a type identifier, for instance, the
first page in the mdb file is 0x00, which no other page seems to share."
"In Jet4, an additional four byte field was added. It's purpose is currently
unknown."
... (more)
2. Working with unstructured data
As challenging as it might be for a programmer without access to
Microsoft's internal documents to extract table structure from a
Microsoft MDB file, the '226 Patent refers to an additional
capability: the ability to infer structure from a stream of data items
that are uploaded without any "information regarding the structure
and/or organization of said data items" (e.g., Claim 37).
The challenge starts in a similar manner to that confronted by the
archaeologists who uncovered the first tablets in Linear A, the written
language of the Minoans around 1800-1450 B.C. They had obtained a
stream of symbols, but didn't know what any of them meant and, if they
were phonetic, did not know any words in the Minoan language. [Despite
more than 100 years of effort, Linear A remains undeciphered to this
day.] A computer program that receives a stream of 1s and 0s must
first decide whether it is a stream of 64-bit "words" for a
PlayStation 3 Cell processor, a stream of 32-bit "words" for an older
Intel Pentium chip, a stream of 8-bit ASCII characters, or a stream of
4-bit "nibbles" holding binary-coded decimal digits.
Suppose that Program 2 of the '226 Patent is able to determine that
the bits in an uploaded file represent 100 decimal digits. That's
tremendous progress over "a string of 1s and 0s", but many
interpretations of these 100 digits remain. The uploaded file could be
a complete 100-digit number. It could and almost surely would
correspond to 100 digits within the infinite sequence of digits of
Pi. It could be ten 10-digit phone numbers. The '226 patent refers to
a program that can figure out, from among the infinite number of
possibilities for interpreting these 100 decimal digits, what the
numbers represent, pick a name for the database table to store this
information, divide the information into rows and columns, pick one or
more column names, and pick data types, e.g., "number" or "date", for
each column.
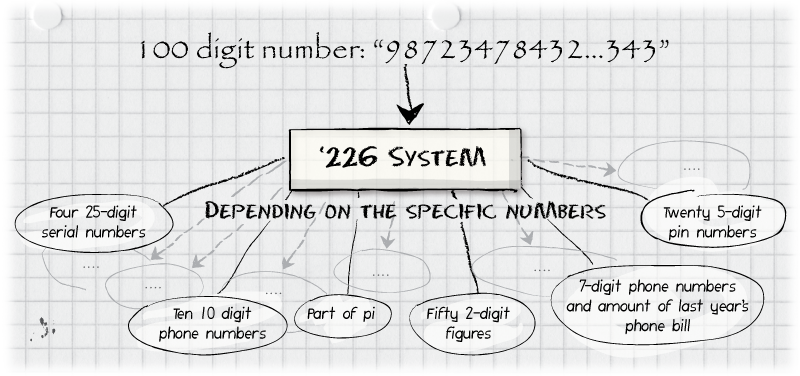
Figure 6: Program 2, referred to in Col. 2:40 of the '226 Patent,
processing uploaded application data that contained no "information
regarding the structure and/or organization of said data items" (Claim
37).
A simpler concrete example is the application data "7567075703". Here
are some possibilities for interpreting these digits:
- a 10-digit phone number, to be stored in a table
phone_numbers
with one column, whole_number, of type char(10).
- two U.S. zip codes, 75670 and 75703, to be stored in a table
zip_codes with one column, five_digit_code,
of type char(5); two rows (or "records") will be inserted
into this table, one for each zip code
- inventory data from a store with 1000 different items to sell,
each with a product ID ranging from 000 to 999; these digits indicate
that, of product ID "756" the store has 70 units in stock and of the
product ID "757" there are just 3. Two rows will be stored in
a table called
inventory with two columns:
product_id char(3), quantity integer.
- a Unix/Linux operating system timestamp, i.e., a date-time
specified in the number of seconds since January 1, 1970 (in this
case, Monday, October 16, 2209 at 9:28 pm Greenwich Mean Time), to be
stored in a table called
important_dates with one column,
unix_timestamp, of type integer.
The '226 patent then populates a computer-readable specification of
everything relevant to the new application. This specification,
similar in concept to that used for the 1998 Siemens Sharenet project
described above, is itself stored in database tables called in the
patent the "data dictionary tables" (Figure 11). The data
dictionary tables have the same names and structure (number and type
of columns) for all applications. Each application, however, will
insert rows with different values into this structure. In other words,
these are the same tables, but populated differently. The '226 patent
provides editing facilities for a human to adjust or change some of
the work done by the automated program in populating the data
dictionary tables. Each change by a human from one of the forms in
Figure 9E through 9AI will result in updating a value in a data
dictionary table or possibly adding or deleting a row.
Once the data dictionary is established, the information from the data
dictionary is read and used to build a SQL schema or data model for
the application itself. The data dictionary was metadata ("data about
data"). Before an application can function, however, there must be
tables that can store data items themselves. A "third program" that
can accomplish this task is referred to in Col. 2:44-45. The "third
program" receives an additional three lines of description in
Col. 5:22-24.
B. Step 3: incorporating existing data
The '226 Patent refers (Col. 2:45) to a program ("Program 4") that will
read the data items from "electronic information ... in many forms,
including PC-based databases (e.g., Microsoft's Access, FoxPro, dBase,
Paradox, etc.), spreadsheets, and text files" (4:49-51) and
insert these data into the application tables that were created at the
end of Step 2. No algorithms are disclosed for this program and no
suggestions are made as to where a programmer might find
specifications for these formats.
C. Step 4: writing application pages
After the data dictionary specification is to the application owner's
satisfaction, the '226 Patent suggests that a computer program
("Program 5") will run to generate a set of computer programs
("application pages"). These generated computer programs are run in
response to requests from end-users at Web browsers. Note that the
patent specification does not suggest any particular computer language
for the application pages, though Claim 3 and similar claims mention
"Java". No algorithms or hints are given for transforming the data in
the "data dictionary" into the software of the application pages, but
the top of Column 3 implies that somehow the data dictionary contains
sufficient information to determine a complete application.
D. Steps 5 and 6: revising the application
An important feature of the system referred to by the '226 Patent is
that the data dictionary and generated computer programs are not
static. If business requirements change, the data dictionary can be
updated. This is done by a sixth program whose existence can be
inferred from various of the Figures 9A through 9AK in the
patent. Some of these figures show forms that an application owner can
use to update information in the data dictionary. This process is
mentioned in Column 6 of the patent, starting at line 32. Somewhat
confusingly, the application owner using the forms in Figures 9A-9AK
is referred to as the "user", which could in other contexts be
understood as "end-user", i.e., a person interacting with the
application pages generated by Program 5.
Once the data dictionary is updated, the SQL schema for the
application database is changed (6:31) and "the application's web
pages are regenerated" (6:30). The "web pages" referred to here are
computer programs that have the ability to send queries to the
application database and that ultimately generate the HTML that is
rendered by the end-user's browser. Thus a layer of
dynamism is added compared to the conventional Web-based database
application. The conventional application includes computer programs
that run in response to page requests, thus making it possible for
end-users to receive a Web page with up-to-date information just
inserted into the database. If the database structure is changed, a
human programmer must be hired to update the conventional application
page scripts. By contrast, the computer programs built and maintained
by the system of the '226 Patent are themselves dynamic and will be
changed automatically when necessary.
X. Summary
Database applications have been among the most useful and important
applications of computer systems since the late 1950s. A Web interface
to a database application enables use by people scattered around the
globe, connecting from desktops, laptops, and smartphones without the
need to install additional software. Developing database applications,
with and without Web interfaces, has been the life's work of hundreds
of thousands of programmers worldwide and has required the skills of
understanding business requirements, predicting user behavior, and
creative software design.
If the programs referred to in the '226 Patent worked, they would
substantially automate nearly every step of the software development
process for a database application. Given a stream of data items,
these programs would infer the structure and organization of the data
and design the SQL schema or data model for an application built
around the data. The programs would fill the newly created application
tables with existing data and generate the computer programs ("page
scripts" or "application pages") necessary for users to work with the
completed database from their Web browsers. Finally, the programs
would keep the complete application up to date as user requirements
change.