Introduction to AOLserver, Part 1
by Philip Greenspun,
illustrated by
Mina
Reimer
(Written in July 1999 for www.linuxworld.com; permanently
installed now in Web Tools Review)
Are you concerned about your Web site's scalability? I'm pretty sure
that as long as I don't get more than 28,000 hits I'll be okay. How can
I be sure? That's how many hits that America Online is serving with the
open-source Web server that I use: AOLserver. Twenty-eight thousand
hits? That's not really so many, is it? One often hears about sites
that get more requests than 28,000 per day, per week, or per month.
With 17 million subscribers, though, America Online is talking about
28,000 hits per second across all of its various Web services
and servers.
AOLserver? It was built in 1994 by Jim Davidson and Doug McKee, two
Unix wizards in Santa Barbara as part of an end-to-end Web publishing
system. The first part of the system was NaviPress, a
what-you-see-is-what-you-get (WYSIWYG) Web page editor. NaviSoft wanted
to permit people without any training maintain Web sites, not
just Web pages. So they produced their own Web server, NaviServer, that
would respond not only to the standard GET and POST methods but also to
the PUT method ("put this page back into the file system on the
server").
How innovative was this? Innovative enough to win every magazine's Best
Web Product award back in early 1995. Journalists gushed about how Tim
Berners-Lee's read-only Web system was finally useful as a collaborative
authoring system. Indeed, Tim himself might have been impressed except
for the fact that he had a graphical editable Web browser, capable of
PUTing content back onto the server, back in 1990. This capability was
taken from users by the authors of the NCSA Mosaic browser and server.
These programmers, who later went on to found Netscape Communications,
put their effort into making Tim's system work on multiple operating
systems and didn't have the energy or ability to retain the editability.
NaviSoft was effectively restoring to Web users what Tim had given them
in the first place.
In a world surfeited with HTML editors, why should anyone care about
what was happening back in 1994? Because Jim and Doug are the best
engineers who've ever attacked the Web server problem, America Online
bought NaviSoft, and now the source code is free and available to anyone
who cares to visit http://www.aolserver.com.
Note: the HTML editor is available from http://www.aolpress.com/; sadly
it is not open-source and they've discontinued support for Macintosh and
Unix versions.
Why You'd Want to Use AOLserver
AOLserver delivers the following features and benefits:
- faster, more reliable, more maintainable scripting
- pooled connections to relational database management systems
- single Unix process gives programmers the ability to cache files or
database results in virtual memory
Let's address each of these in turn.
faster, more reliable, more maintainable scripting
The traditional 1993-style dynamic Web service is backed by CGI scripts.
Client requests a page, server starts a separate program (the CGI
script), CGI script returns results to the connection. You can get at
least a 10-fold improvement in server throughput by running
page-generation programs inside the Web server
process. AOLserver, like most Web servers, has an API to facilitate you
writing C programs that run inside the AOLserver process. The problem
with this approach is that an error in your C program can crash the
entire Web service.
The AOLserver developers solved this problem by compiling a Tcl
interpreter into their program. Why is Tcl better than C for Web
scripting? First, it is safe. An error in a Tcl script will break one
page, not the entire server. Second, Tcl is interpreted so it is much
faster to develop code and fix bugs than in a compiled language such as
C or Java. Finally, because the Tcl interpreter is available at
run-time, you can take advantage of powerful programming ideas like
programs that generate programs.
NaviSoft's choice of Tcl illustrates all the elements that need to come
together before an open-source software package can be adopted. The Tcl
interpreter was free, open-source, and explicitly designed to be
included in larger programs. Moreover, the authors produced documents
with titles like "How to compile the Tcl interpreter into your C
program". The interpreter as released by John Ousterhout wasn't
thread-safe, but it was simple enough that Jim and Doug could find the
parts of Tcl that weren't thread-safe and make them thread-safe. We can
conclude from this example that the open-source programs with the most
impact will be those that are the easiest to understand and adopt, not
those with the most features.
AOLserver Tcl applications tend to be more maintainable than
applications developed for other Unix Web servers. In large part this
is due to the standardized API. For example, suppose Joe Hacker tells
you that he has written an Web-based system to do comparative shopping,
it isn't working properly and he's about to leave for vacation. The
system fetches Web pages from other sites, parses them to find the
prices, then returns a summary to the user. Would you mind debugging it
for him?
Suppose that he says he is using Apache or Netscape Enterprise Server.
This tells you nothing about the programs implementing his service,
other than that they will be for a Turing Machine. Neither Apache nor
Netscape Enterprise provide powerful or commonly used scripting systems.
So Joe Hacker might just as well have said "I used Unix" or "I used a
computer." Will the site be done in Perl CGI scripts? The PHP
templating language? Java Servlets? The Cold Fusion templating system?
The Chili system for parsing Microsoft Active Server Pages? JavaScript
inside the Netscape server's LiveWire system? Common Lisp CGI scripts
(don't laugh; Yahoo Store was built in Lisp and sold for $47 million)?
Python? C? Will you be exposed to the complexity and unreliability of
an application
server?
If Joe Hacker goes on vacation and leaves you with an AOLserver-based
comparative shopping application, you can be 99% sure that the
programming was done in Tcl running inside AOLserver, that all of the
code handling a particular page will be found within two directories,
that fetching of pages from foreign servers was done with the
ns_httpget API call, and that when the system requires
connectivity to a database management system it will be done through the
ns_db API call.
AOLserver supports CGI and its design facilitates the construction of
Apache-style modules. However, the AOLserver team provides such
exquisite code, documentation, and cultural support for one style of
programming that nearly everyone uses that style ("leave the truly hard
stuff to the database; write all the pages and glue code in the Tcl
API").
pooled connections to relational database management systems
Historically, talented programmers have been ignorant of the capabilites
of database management systems. Thus, even when an application seems to
be a natural fit for Oracle, a programmer will come up instead with a
sui generis flat-file database management system. It usually
works fairly well for the problem as originally conceived but the
long-term consequences of using slapped-together database management
software are painful.
AOLserver was designed from scratch to connect to the most popular kind
of database software: the relational database management system
(RDBMS). In the CGI world, the Web server starts up a new program every
time a request comes in from a browser. The CGI script then opens up a
connection to the RDBMS, an operation that generally requires Unix to
start another program (fork). If you are getting 20 hits per
second under this scheme, your computer is starting 40 new programs
every second.

|
| AOLserver database connection-pooling architecture.
20 requests per second
for database-backed pages = 0 new programs started per second.
| Traditional CGI architecture. 20 requests per second
for database-backed pages = 40 new programs started per second.
|
AOLserver runs as a single Unix process. You can deliver the 20 dynamic
pages per second of our example without your server having to start any
new programs. If those pages need to connect to Oracle, they simply ask
AOLserver to let them use an already-open connection from a configurable
pool. Note that this ability to pool database connections is a
consequence of AOLserver's one-process-with-threads architecture. With
a process-pool Web server such as Apache, nothing stops you from linking
in the Oracle C libraries. Your Apache server can then function as an
Oracle client. However, there would be no way to share a database
connection among Apache server processes. What's the bottom line
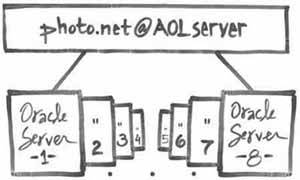
difference? A site like http://www.photo.net can serve 700,000 hits per
day, to about 120 simultaneous users at once, with one AOLserver process
holding open eight connections to Oracle. That's a total of nine Unix
processes (one AOLserver, eight Oracle). With Apache, providing the
same level of service from photo.net would require 120 Apache server
process, each of which held open two connections to Oracle: 360
processes total.
Another dividend from the single-process architecture of AOLserver is
that you can cache stuff in AOLserver's virtual memory. For example,
consider the Bill Gates Personal Wealth Clock (http://www.webho.com/WealthClock).
It gets as many as two hits per second at peaks. Yet it relies on
invoking CGI scripts running at foreign Web sites where they probably
wouldn't appreciate getting hammered by my server. The solution is to
cache the page in AOLserver's virtual memory. Again, this is something
you could do with a process-pool server such as Apache but you'd be
gradually building up 120 separate copies of the same data.
vs.

Caching is also useful for expensive database calculations, e.g., sweep
the entire classified ads table to find out how many ads are in each
category. This needn't add complexity to your source code: I distribute
a utility function called Memoize that you can wrap around
any Tcl statement and the result will be cached. AOLserver itself
provides built-in caching for frequently-accessed static files and
templates (see the nscache module in the 2.3 release). You can get an
expensive application server if you like but remember that you'll never
get higher performance than a threaded Web server delivering bits from
its own virtual memory.
comparison to Apache
People often ask me how AOLserver compares to Apache. It is kind of an
odd question since Apache itself, a Web server for static files and CGI
scripts, only attacks 5% of the problem solved by AOLserver. The simple
answer is that "You can download AOLserver and install in 30 minutes and
be up and running serving static files and CGI scripts, just like you
were with Apache."
I think the real question is "How does AOLserver compare to Apache plus
the collection of modules and public-domain source code typically
cobbled together at the average site running Apache?"
| AOLserver
| Apache
|
| Weak support for ISPs hosting thousands of domains, each
for a small customer with mostly static files.
| Strong support for ISPs.
|
| Strong support for database-backed Web services.
| No built-in support for building a database-backed Web
service. Every programmer cobbles together a different set of modules
and home-grown code.
|
| Good open-source libraries available for doing
sophisticated things, e.g., the ArsDigita Community System for building
online communities and ecommerce sites.
|
For Perl users, vast open-source libraries available. Especially useful
to novice programmers.
|
| Small community of wizards. Most AOLserver-backed sites
are connecting to relational databases to support personalization or
desktop app replacement. Some are cranking out thousands of hits per
second within AOL.
| Large community of programmers, especially for Perl
scripting.
|
| All programmers in community use same language and same
high-level procedure calls (since they are built-in).
| Community of programmers uses a plethora of languages.
Within a particular language, each programmer uses a different set of
high-level procedure calls (since so little is built into the server).
|
| High performance for serving static files.
| Good enough performance for serving static files.
|
| Very high performance for serving script- and
database-backed sites.
| Adequate performance for serving script- and
database-backed sites, but only if set up and programmed by
wizards.
|
| New programmers are trained via a rigid curriculum of
problem sets developed for a course at MIT and now available at other
universities and in a three-week boot camp (see
http://www.photo.net/teaching/boot-camp.html;
all
the course materials are free).
| New programmers are trained via reading
Teach
Yourself Cgi Programming With Perl 5 in a Week
|
| New server software and ideas from one of the world's
highest-volume Web publishers, plus a bit of help from the community
of users. Releases come in response to major new needs at AOL.
| Lots of help from a large community of users, but with no
strong central push from salaried developers, releases tend to be
infrequent and insignificant in terms of new capabilities. (This is one
of the dirty secrets of the open-source world; it is easy to get new
modules contributed but hard to get everyone coordinated enough to make
major changes in the core.)
|
|
|
|
|
|
|
|
|
|
If you're using Apache now and are happy with it, I don't recommend switching.
At the end of the day you've got a von Neumann computer that is somewhat
less powerful than a Turing Machine. If you install AOLserver, you'll
have a von Neumann computer that is somewhat less powerful than a Turing
Machine. A good programmer with Apache will get the job done. A good
programmer with AOLserver will get the job done. Suppose you're running
Perl CGI scripts on Apache. Would AOLserver run 10 times faster? Sure.
On the other hand, www.cisco.com manages to sell $1 billion in
merchandise annually with Perl CGI scripts. It is always easier and
safer to plug in more processor boards than to switch tools.
What if you're starting from scratch? If you're building an online
community or some other kind of database-backed Web service, I recommend
AOLserver. If you're going into the $14.95 per month per site business,
Apache seems to have a lot of useful modules.
The Open-Sourcing Of AOLserver
AOLserver started life as the farthest thing possible from open-source.
NaviSoft was a privately-funded start-up company and NaviServer was
licensed to commercial Web publishers at $5000 per machine. The
transformation from $5000, closed-source to free, open-source started in
1994. Official industry visionaries such as Bill Gates were dismissing
the potential of the Internet and open standards. Official Internet
visionaries were throwing rocks at America Online and their users.
What was AOL doing? Sending its best technology people out on an
Internet shopping spree. Among other acquisitions, AOL bought the best
Internet backbone company (ANS), the best Web tools company (NaviSoft),
and the best full-text search engine company (PLS).
AOL needed this technology and wanted the developers of the various
products within shouting distance. However, the revenue stream from
software products such as PLS and AOLserver wasn't significant compared
to their core business. As far as I can tell, there are a couple of
overall styles available to businesses. The first is "do anything, no
matter how shabby, immoral, or degrading for the last 5%". Microsoft
falls into this category. All of the practices for which the Federal
Government is suing Microsoft are attempts by them to get the last 5%.
They'd be 95% as rich if they'd asked PC vendors to pay for Windows on
PCs shipped with Windows, but they couldn't resist forcing the PC
vendors into paying for Windows licenses even when a computer shipped
with Linux or some other OS.
An alternative style is "we don't need the last 5%." America Online
falls into this category, at least as far as the software products they
acquired go. They could have continued to charge money for software
licenses and collected a few $10s of millions. They could have said "We
bought it and we're going to use it internally; it would cost us money
to distribute it so we're not going to make it available anymore." But
instead they said "We're going to use it internally and we'll make it
available to you for free if you'd like to use it also; we don't want
the old user base for this product to be angry with us."
from "free" to "free and open-source"
Is "free" as good as "free and open-source"? In the short run,
probably better. If you're trying to push the state-of-the-art in
Web-supported collaboration, the last thing you want to do is grovel
around in someone else's C code, especially when that C code is many
layers below the users' problem. Remember: users can't tell what Web
server or RDBMS you're using.
In the long run, however, an open-source program will always be more
powerful than closed-source packaged solutions when the application
area is evolving. Commercial software companies are adept at
copying the innovative systems of the 1960s and 1970s but they generally
aren't nimble enough to adapt to changing user needs.
Toward the end of 1998, I found myself running 200 Web
services with AOLserver, sitting on a library of 100,000 lines
of AOLserver Tcl code, and teaching a course at MIT where the students
use AOLserver in their labs. Looking at the crop of Apache modules
available at the time, it seemed to me that the Apache crowd was about
halfway caught up to where AOLserver was in 1994. I extrapolated out
another four years and thought "there will be some way-cool Apache
modules and I'll be sitting here programming AOLserver by myself."
How to convince AOL to open-source AOLserver, though? In dealing with a
big company, the hardest thing is usually figuring out with whom to
talk. My friends on the AOLserver development team suggested talking to
Barry Appelman, the executive in charge of server-side technology at AOL.
Appelman is credited with coming up with the buddy list idea for AOL
Instant Messenger (used by 35 million people) and
makes sure that AOL's Unix servers are responsive to the 17 million AOL
subscribers. So I sent the guy some email:
Dear Mr. Appelman,
I would like to propose that AOL work with the MIT Laboratory for
Computer Science to turn AOLserver into an open-source product like
Apache or the Linux operating system.
Our selfish interest: We use AOLserver here at MIT for research and
education. With the source code, some of our more creative graduate
students and researchers could add interesting capabilities. We also
think it would give our open-source application code more credibility.
Publishers don't want to take the risk of adopting something for which
they don't have the source code (hence the popularity of Apache).
In order to sell AOL on the idea, here are some potential advantages:
1) access to improvements made by developers worldwide and at MIT in
particular; imagine having another few hundred programmers at your
disposal and you don't have to pay them.
2) better access for recruiting MIT computer science majors (bachelor's,
master's, and PhD) to work at AOL
3) better access to MIT computer science researchers. Note that one
floor above me at Tech Square is Dave Clark, the guy who developed
Internet Protocol. One floor below is Tim Berners-Lee, the guy who
developed the Web.
4) better access to training materials that you can use in-house at AOL;
we're going to be teaching a couple of courses in the next 6 months that
introduce students to RDBMS-backed Web service development using
AOLserver (see http://www.photo.net/wtr/thebook/ for the text).
Note that we have considerable experience in this area. The bulk of
Apache was developed in our building by Robert Thau, one of our PhD
students. Project GNU, the original free software movement and source
of most of the software in a Linux distribution, was started in our
building in the mid-1980s by Richard Stallman (who won a MacArthur
fellowship for his efforts). I feel confident that we could make
open-source AOLserver a big success.
-- Philip Greenspun
There was some cunning to this email message. I didn't know Appelman or
his situation, but I knew that no company is happy with the aggregate
capabilities of its software developers or comfortable with its
recruiting strategy for software developers. So my first two points
were addressed to those. My third point, trotting out the famous names
of MIT Computer Science, was a complete fraud. I'd never heard either
Clark or Berners-Lee utter one sentence on the subject of HTTP server
technology and couldn't imagine either caring whether a site was served
using AOLserver, Apache, or the original CERN server for that matter.
The fourth point was again targeted to the big company executive inside
Appelman. A big company's #1 concern is how to recruit the right
people. Their #2 concern is how to train them. So I offered course
materials.
This artfully crafted appeal worked so well that ... Appelman didn't
respond to the email. I was on the phone with Doug McKee a month later
and he said "Barry's usually on AIM at night; just AIM him." I followed
Doug's advice and got Appelman to dredge my message out of his inbox and
read it. It turned out that he didn't have any objections to
open-sourcing AOLserver; it just wasn't something that they'd thought
about. We went back and forth for a few hours over AIM and by early
January 1999 we had basic agreement:
- AOL would spend some intensive developer effort cleaning up the code
before releasing it to the world's scrutiny; the goal would be to
open-source the 3.0 version of the server
- MIT would run a developer's community for programmers interested in
contributing to open-source AOLserver; the initial goal would be to
collaborate around the contribution of modules rather than have everyone
checking code into a single CVS tree. MIT would build software to
support this collaboration (see http://www.photo.net/wtr/acs/open-source.html
and www.aolserver.com for
the running result).
- AOL's lawyers would figure out the exact license that could be
used. At MIT we usually just stick something about the GNU General
Public License (GPL) on our code and are done with it. It wasn't clear
that AOL could do this, however, because they'd relied on some
commercial libraries (e.g., SSL) that they didn't have the rights to
redistribute except in binary form.
Did I heroically overcome obstacles to get AOL to stick to this plan?
No. Barry Appelman delegated the overall project to Lin Jenner and Eric
Flatt. Ben Adida wrote the software development manager extension to
our toolkit. Hal Abelson, the best educator in our department at MIT
and paradoxically the most legal-minded, argued eloquently and
ultimately persuasively that America Online could use the GPL. Jim
Davidson, AOLserver's original architect, and George Nachman worked like
monsters on the code. We got everything done by mid-June 1999, more or
less as planned.
Why tell this story? Some day you might need to convince a company to
open-source a software tool. Companies have seemingly
infinite money but the shortage of truly gifted software developers is acute
(see Chapter 17 of Philip and
Alex's Guide to Web Publishing for my theory on why). A
compelling argument will take the following form:
- the tool is not the key to your business
- if you need a new feature, it would be nice to be able to hire
someone off the street already experienced with the guts of your tool
- a vibrant community of users for your tool will save you money, give
you new ideas, and make it easier for you to hire developers from the
community
- (something I didn't add for Appelman) it is much easier to hire a
great programmer for an open-source project where he or she knows that
the work won't be hidden or wasted
Introduction to AOLserver Programming
There are three ways to program AOLserver:
- C code running inside AOLserver (the C API)
- CGI scripts running outside of AOLserver (standard CGI interface)
- Tcl scripts running inside of AOLserver
I'm not going to cover the first two ways in this article. C code
running inside any Web server is too dangerous for day-to-day
build-a-page use. The C API is only useful to people building modules
and database drivers. Nor will I cover CGI. Once you've followed the
configuration instructions in the AOLserver administration document at
www.aolserver.com, CGI
scripting with AOLserver is the same as with any other Web server (this
is sort of the point of CGI).
For the reasons noted in the introduction, most AOLserver developers use
the Tcl API and we will focus on that. Inexperienced Web developers are
sometimes fooled by the simplicity of Tcl into thinking that we are
restricted to developing simple Web sites. They don't have the depth to
realize that none of the technical challenge in developing a Web service
lies in the authoring of the code for one page. The challenge is in
realizing that the Web service itself is an object. The object has
state, typically stored in a relational database management system. The
object has methods (the URLs) and arguments to those methods (the inputs
of the forms that target the URLs). The engineering challenges of Web
development are (a) coming up with the correct data model for the object
state, (b) coming up with a correct and maintainable organization of
URLs, and (c) defining the semantics of each URL. By the time an
individual page is constructed, the engineering challenge is over and it
doesn't really matter whether you build that script in a simple language
(e.g., Perl or Tcl) or a complex powerful language (e.g., Common Lisp or
Java).
After four years of developing in Tcl, I have discovered some things
that I like about the language. It is very small and simple with few
syntax baroqueries. A good programmer can learn Tcl in two hours -- we
find that our students at MIT have picked it up on their own during the
first few days of the course. Tcl is good for handling strings, which
is nice since the only data type one can read from Oracle is a string
and the only data type one can read from or write to a Web connection is
a string. Tcl is extremely reliable; I've never encountered a bug in
the Tcl interpreter or managed to crash AOLserver via a Tcl programming
mistake. The Tcl interpreter is available at run-time, which makes it
easy to add things to the language such as my memoization facility. The
interpreter being available at run-time also enables you to write
programs that write programs and store Tcl programs in the database for
execution during page service. The bottom line? Tcl's deficiencies
waste about four hours of my time per year compared to the mythical
ideal language.
If you're a die-hard Java nerd, don't be discouraged. When you need to
do something that calls for a tower of abstraction, you can still write
all the Java code you want and have it run inside the Oracle RDBMS
server. Your AOLserver Tcl procedures can invoke this Java program as
part of its normal interaction with the database on every page.
how to make AOLserver run some Tcl code
There are four ways to get AOLserver to run some Tcl code:
ns_register_proc GET /foo
-- instead of looking in the file system for a file to serve, run a specified procedure
whenever a user requests a URL starting with "/foo"
ns_register_filter GET /foo*
-- in addition to what else the server might do in serving a
request starting with "/foo", also run run a specified procedure at a
specified time (before or after the page is served)
foobar.tcl -- if a file anywhere under the Web server
root ending in ".tcl" is requested, grab its contents and feed it to the
built-in Tcl interpreter
foobar.adp -- if a file anywhere under the Web server
root ending in ".adp" is requested, assume that most of it is HTML but
parse it to look for embedded Tcl code to interpret
We will address each of these styles of programming in turn.
Style 1, Case 1: ns_register_proc used for redirection
Back in 1995, we moved a Web site from an overloaded shared computer
called "martigny.ai.mit.edu" to a dedicated server called
"www-swiss.ai.mit.edu". There were a lot of links and bookmarks out
there explicitly referencing Martigny and we wanted users who requested
"http://martigny.ai.mit.edu/samantha/" to get redirected to
"http://www-swiss.ai.mit.edu/samantha/". We did this by running
AOLserver on Martigny and putting a small file of Tcl code into its
private Tcl library.
First, we tell AOLserver to feed all requests to a Tcl procedure instead
of looking around in the file system:
ns_register_proc GET / martigny_redirect
This is a Tcl procedure call. The procedure being called is named
ns_register_proc. All of the procedures in the
NaviServer Tcl API begin with
"ns_". ns_register_proc
takes three arguments: method, URL, and procname. In this case, we're
saying that HTTP GETs for the URL "/" (and below) are to be
handled by the Tcl procedure martigny_redirect:
proc martigny_redirect {} {
append url_on_swissnet "http://www-swiss.ai.mit.edu" [ns_conn url]
ns_returnredirect $url_on_swissnet
}
This is a Tcl procedure definition, which has the form "proc
procedure-name arguments body". martigny_redirect takes no
arguments. When martigny_redirect is
invoked, it first computes the full URL of the corresponding file on
Swissnet. The meat of this computation is a call to the API procedure
ns_conn asking for the URL that was part of the request
line.
With the full URL computed, martigny_redirect's second body line
calls the API procedure ns_returnredirect. This writes back to the
connection a set of 302 redirect headers instructing the browser to
rerequest the file, this time from "http://www-swiss.ai.mit.edu".
Style 1, Case 2: ns_register_proc used to serve a whole page
A user once warned me of a "security hazard" in that the source code for
many of my applications could be obtained by appending a tilde character
(~) to the URL. This is because the Emacs text editor that I use will
often write backup files with names like "foobar.tcl~". Since it
doesn't end in ".tcl", AOLserver will normally just stream it out. This
doesn't upset me personally since all of my software is open-source.
However, many users of the ArsDigita Community System have developed
proprietary modules that form the basis of their business. For them, we
stuck in a private Tcl library file:
ns_register_proc GET /*~ ad_hide_tilde_files
ns_register_proc POST /*~ ad_hide_tilde_files
ns_register_proc HEAD /*~ ad_hide_tilde_files
proc ad_hide_tilde_files {ignore} {
ns_return 200 text/plain "You asked for a URL that ends in ~.
This would be a backup file generated by the Emacs text editor
and is probably not what you want."
}
Three calls to ns_register_proc are necessary to embrace
all the possible HTTP methods via which a Web client might request a URL
ending in ~. All those requests are passed to
ad_hide_tilde_files, a procedure with one argument
(ignore), that calls one procedure: the AOLserver API call
ns_return. This API call takes three arguments: the HTTP
status code (200 is normal), the MIME type of the document being sent
back to the client (text/plain in this case), and a message for display
in the browser window.
Style 1, Case 3: ns_register_proc used to make dynamic pages look static
In ancient times, photo.net was a purely static Web site. The URLs
ended in ".html" because that's how the files in the file system were
named. If you visit http://www.photo.net/photo/tutorial/light.html
right now, you'll find the original static content plus user-contributed
comments and links that are pulled from the database. How is that
accomplished? Here is a simplified fragment from http://software.arsdigita.com/tcl/ad-html.tcl:
ns_register_proc GET /*.html ad_serve_html_page
proc ad_serve_html_page {ignore} {
set url_stub [ns_conn url]
set full_filename "[ns_info pageroot]$url_stub"
# read the contents of the file into the variable WHOLE_PAGE
set stream [open $full_filename r]
set whole_page [read $stream]
close $stream
# use the Tcl REGEXP facility to look for a "close body" HTML tag
if { [regexp -nocase {(.*)</body>(.*)} $whole_page match pre_body post_body] } {
# there was a "close body" tag, let's try to insert a comment
# link at least
# (but before we do anything else, let's stream out what we can, note that
# this is almost the entire page, before we've even gone to Oracle)
ReturnHeaders
ns_write $pre_body
if { [catch { set db [ns_db gethandle -timeout -1] } errmsg] || [empty_string_p $db] } {
# the non-blocking call to gethandle raised a Tcl error; this
# means a db conn isn't free right this moment, so let's just
# return the page with a link
ns_log Notice "DB handle wasn't available in ad_serve_html_page"
ns_write " .. hyperlinks to comments and contributed URLs ... "
} else {
# we got a db connection
# figure out if we're supposed to display or accept comments and links
set selection [ns_db 0or1row $db "select * from static_pages where url_stub = '$url_stub'"]
set_variables_after_query
if { $inline_comments_p == "t" } {
# query the database for comments and links, then write them out
...
}
}
} else {
# couldn't find a
tag
ns_return 200 text/html $whole_page
}
}
What looks to a Web client like a static file pulled from the file
system actually results in execution of the following algorithm:
The AOLserver Dynamic Pages (ADP) facility in AOLserver uses the
same syntax as ASP. The page author is writing HTML most of the time
but a <% sequence will escape into Tcl. Here is a
simple page distributed the ArsDigita Community System. The idea is
to give publishers a standard privacy policy that can pick up the
name of the site, the name of the publisher, and basic page style from
Tcl procedures defined site-wide.
The ADP facility is even more useful when invoked programmatically
from a .tcl page or ns_register_proc. For example, the
ArsDigita Community System style package (see http://www.photo.net/doc/style.html)
provides for a division of labor between programmers and designers.
The programmer builds a .tcl page. The designer uploads templates to
a separate directory tree, each template named to correspond to a .tcl
page.
The programmer's job is no longer to write bytes to the user's browser
but rather to query the database and set up variables for use by the
template. At the end of every .tcl page, the programmer calls
ad_return_template. This procedure scores all the
relevant templates against user and publisher language and graphics
preferences, finds the highest-scoring template and calls the
ns_adp_parse API call to stuff the template with the
computed variables.
The end result? You've got a multi-lingual site, with graphics and
text-only versions, that can be given a complete graphical facelift
without involving the programmer.