
|
|
Chapter 15: Case Studies |
 This chapter contains six case studies, each with some actual source
code. I present user interface, interaction design, and data modeling
ideas that should be useful to you in many contexts. This chapter is not
a step-by-step guide. If it were, it would be 800 pages long, absurdly
boring, and extremely tool-specific.
This chapter contains six case studies, each with some actual source
code. I present user interface, interaction design, and data modeling
ideas that should be useful to you in many contexts. This chapter is not
a step-by-step guide. If it were, it would be 800 pages long, absurdly
boring, and extremely tool-specific.
Because I'm afraid that your eyes will glaze over and you'll skip this, I'll try to give you a hint of what is in store. Case 1 is straightforward and dull. It is intended to help you understand how AOLserver Tcl works with a simple mailing list registration application. Feel free to skip it. Case 2 shows how to generalize this application so that many static Web services can share a single RDBMS-backed service. It is a powerful idea that I have used at least a dozen times. Case 3, the birthday reminder system, introduces the idea that less can be more. It does less than a calendar management program but is easier to use. Case 3 also demonstrates how to build a back-end to loop through a database table and send e-mail when necessary. In doing so, it addresses in a practical way an important question about concurrency and RDBMS.
Case 4, the bulletin board system, shows how important it is to have all of your services run from the same database management system and users table. It also raises the interesting issue of whether a 99 percent reliable system isn't better than a 100 percent reliable system. Case 5, ArsDigita Quizze, shows how to use a server-side database to keep session state, preserve a user's ability to go back and forward on pages, yet keep the user from using the Back button to cheat on a quiz. Case 6 covers the Uptime server monitoring system and brings up issues of maintainability for public Internet services.
I hope that you're inspired. If you don't have the patience to read the source code then please at least skim the text underneath each new case headline.
 We went through this in the first chapter on RDBMS-backed sites, but now
let's do it over again with actual code. Remember that you want a
mailing list system for your site. Users can add and remove themselves,
supplying email addresses and real names. You want to be the only one
who can view the list and the only one who can send mail to the list.
We went through this in the first chapter on RDBMS-backed sites, but now
let's do it over again with actual code. Remember that you want a
mailing list system for your site. Users can add and remove themselves,
supplying email addresses and real names. You want to be the only one
who can view the list and the only one who can send mail to the list.
create table mailing_list ( email varchar(100) primary key, name varchar(100) );
insert into mailing_list (email,name) values ('philg@mit.edu','Philip Greenspun'); delete from mailing_list where email = 'philg@mit.edu';
(see<html> <head> <title>Add yourself to the mailing list</title> </head> <body bgcolor=#ffffff text=#000000> <h2>Add yourself to the mailing list</h2> <form method=post action=add.tcl> <table> <tr><td>Name<td><input name=name type=text size=35> <tr><td>email<td><input name=email type=text size=35> </table> <p> <input type=submit value="Add Me"> </form> </body> </html>
 for this form
rendered by a Web browser)
... and a form so that someone can delete himself from the list ...
for this form
rendered by a Web browser)
... and a form so that someone can delete himself from the list ...
(see<html> <head> <title>Remove yourself from the mailing list</title> </head> <body bgcolor=#ffffff text=#000000> <h2>Remove yourself from the mailing list</h2> <form method=post action=remove.tcl> <table> <tr><td>email<td><input name=email type=text size=35> </table> <p> <input type=submit value="Remove Me"> </form> </body> </html>
for this form
rendered by a Web browser)
Here is an AOLserver Tcl script to process the "add me" form. The script will
# call philg's magic functions to set local variables
# to what the user typed into the form
set_the_usual_form_variables
# name, email, QQname, QQemail are now set
# get an open database connection from the AOLserver
set db [ns_db gethandle]
# Check for errors in user input before doing anything else
# we use the Tcl REGEXP command to see if the email variable
# has the following form: 1 or more ASCII characters (.+) followed
# by the "at sign" (@) then 1 or more ASCII characters (.+)
# followed by at least one period (\.) then 1 or more ASCII characters (.+)
if { ![regexp {.+@.+\..+} $email] } {
# the REGEXP didn't match
ns_return 200 text/plain "Your email address doesn't look right to
us. We need your full Internet address ..."
# RETURN terminates the AOLserver source.tcl command
# so none of the code below this point will be executed
# if the email address had an incorrect form
return
}
# if we got here, that means the email address was OK
if { $name == "" } {
# the variable NAME was an empty string
ns_return 200 text/plain "You didn't give us your name..."
# this terminates the AOLserver source.tcl command
return
}
# Error checking complete; ready to do real work
# construct the SQL query using the versions of the form
# variables where apostrophes have already been doubled
# so that names like "O'Grady" don't cause SQL errors
set insert_sql "insert into mailing_list (email, name)
values ('$QQemail','$QQname')"
# we execute the insert inside the Tcl function CATCH
# if the database raises an SQL error, the AOLserver API
# call ns_db dml will raise a Tcl error that would result
# in a "Server Error" page being returned to the user. We
# don't want that, so we catch the error ourselves and return
# a more specific message
if [catch { ns_db dml $db $insert_sql } errmsg] {
# the insert went wrong; the error description
# will be in the Tcl variable ERRMSG
ns_return 200 text/plain "The database didn't accept your
insert, most likely because your email address is already on
the mailing list..."
} else {
# the insert went fine; no error was raised
ns_return 200 text/html "<html><head><title>$email Added</title>
</head>
<body bgcolor=#ffffff text=#000000>
<h2>$email Added</h2>
<hr>
You have been added to the <a href=/index.html>www.greedy.com</a>
mailing list.
<hr>
<address>webmaster@greedy.com</address>
</body>
</html>
"
I was feeling pretty good about the code above until Jeff Friedl, author of the superb book Mastering
Regular Expressions (O'Reilly 1997), pointed out that
"philg @mit.edu" or "5 @ $1.95" would slip through my caveman regexp.
If I didn't want to adopt the three-page regexp in Appendix B of his book
then at least I could do
"^\[^@\t ]+@\[^@.\t]+(\.\[^@.\n ]+)+$"
The AOLserver Tcl script to process the "remove me" form is much simpler.
set_the_usual_form_variables
# now email and QQemail are set as local variables
# ask for a database connection
set db [ns_db gethandle]
# note that the dual calls to the SQL UPPER function
# ensure that the removal will be case insensitive
set delete_sql "delete from mailing_list
where upper(email) = upper('$QQemail')"
# execute the delete statement in the database
ns_db dml $db $delete_sql
# call the special AOLserver API call ns_ora resultrows
# to find out how many rows were affected by the delete
if { [ns_ora resultrows $db] == 0 } {
# 0 rows were affected
ns_return 200 text/plain "We could not find <code>\"$email\"</code> on the mailing list ..."
} else {
# the delete affected at least one row so removal must
# have been successful
ns_return $conn 200 text/html "<html><head><title>$email Removed</title>
</head>
<body bgcolor=#ffffff text=#000000>
<h2>$email Removed</h2>
<hr>
You have been removed from the <a href=/index.html>www.greedy.com</a>
mailing list.
<hr>
<address>webmaster@greedy.com</address>
</body>
</html>
"
} "Mailing List"? This sounds vaguely like Case 1. It
is. Vaguely. It turns out that you need mailing lists for four other
services that you offer. Also, 10 of your friends want to run mailing
lists for their sites. You'd be happy to give them your code, but you
know that they aren't willing to endure the pain of maintaining a
relational database management system just for this one feature. They
are grateful, but "Oh, while you're at it, would you mind allowing
us also to store Snail Mail information?"
"Mailing List"? This sounds vaguely like Case 1. It
is. Vaguely. It turns out that you need mailing lists for four other
services that you offer. Also, 10 of your friends want to run mailing
lists for their sites. You'd be happy to give them your code, but you
know that they aren't willing to endure the pain of maintaining a
relational database management system just for this one feature. They
are grateful, but "Oh, while you're at it, would you mind allowing
us also to store Snail Mail information?"
Can you make the code generic? You just need an extra table to store information about each of your and your friends' services.
create table spam_domains (
domain varchar(100) primary key,
backlink varchar(200), -- a URL pointing back to the user's static site
backlink_title varchar(100), -- what to say for the link back
blather varchar(4000), -- arbitrary HTML text that goes at the top of the page
challenge varchar(200) default 'Your mother''s maiden name',
response varchar(50),
maintainer_name varchar(100),
maintainer_email varchar(100),
-- send email when a person adds himself?
notify_of_additions_p char(1) default 't' check (notify_of_additions_p in ('f','t')),
-- booleans to decide which information will be collected; name & email are always done
title_and_company_p char(1) default 'f' check (title_and_company_p in ('f','t')),
snail_mail_p char(1) default 'f' check (snail_mail_p in ('f','t')),
demographics_p char(1) default 'f' check (demographics_p in ('f','t')),
-- people who are distributing software, for example, want the
-- post-add-me page to give download instructions, if NULL, we just
-- cough up the usual text
custom_confirm_after_add_me varchar(4000),
-- if they are storing extra columns then the next item will non-NULL
extra_columns_table_name varchar(100)
);
Rather than a password, which your friends might forget and then bug you to manually retrieve from the database, you store a challenge question of their choice, e.g., "mother's maiden name", and their response.
You keep track, per domain, of the name and email address of the list
maintainer. If the notify_of_additions_p column is set to
true then your "add me" script will send email to the
maintainer when someone new adds himself to the list. You keep track of
how much data is to be solicited in the Boolean columns such as
snail_mail_p (the "add me" form will ask for postal mail
address). For publishers who are using the system to collect
registration info before offering software to download, you provide the
custom_confirm_after_add_me column. Those folks might want
to solicit information that you never anticipated, such as
operating_system so you build into the system the ability
for forms and reports to have extra columns, stored in a separate
table. That table's name is kept in a domain's
extra_columns_table_name column.
Once the new spam_domains table is defined, you need to
beef up the mailing list table as well. It would be possible to build
this system so that it defined a separate table for each new domain, but
I think it is cleaner to add a domain column to the mailing list table
as long as we're adding all the extra columns for physical mail and
demographics:
create table spam_list (
domain varchar(100) not null references spam_domains,
email varchar(100) not null,
name varchar(100),
-- info for 'snail_too'
title varchar(100),
company_name varchar(100),
line1 varchar(100),
line2 varchar(100),
city varchar(50),
state varchar(50),
postal_code varchar(20),
country char(2), -- ISO country code
phone_number varchar(20),
-- info for snail_plus_demographics
birthday date,
sex char(1) check(sex in ('m','f')),
primary key( domain, email )
);
primary key( domain, email ) constraint at the end of
the table definition.
How does all this work? If you visit http://www.greenspun.com, you can see the whole system in action. Here's an example of how the add-me.html form has been replaced by a Tcl procedure:
set_the_usual_form_variables
# QQdomain
set db [ns_db gethandle]
set selection [ns_db 1row $db "select *
from spam_domains
where domain='$QQdomain'"]
set_variables_after_query
set form_fields "<tr><td>Name<td><input name=name type=text size=35>
<tr><td>email<td><input name=email type=text size=35>"
if { $title_and_company_p == "t" } {
append form_fields "<tr><td>Title<td><input name=title type=text size=35>
<tr><td>Company Name<td><input name=company_name type=text size=35>"
}
if { $snail_mail_p == "t" } {
append form_fields "<tr><td>Address Line 1<td><input name=line1 type=text size=35>
<tr><td>Address Line 2<td><input name=line2 type=text size=35>
<tr><td>City, State, Postal Code<td><input name=city type=text size=12>
<input name=state type=text size=6>
<input name=postal_code type=text size=8>
<tr><td>Country<td><input name=country type=text size=3 limit=2> (ISO Code, e.g., \"us\", \"fr\", \"ca\", \"au\", etc.)
<tr><td>Phone Number<td><input name=phone_number type=text size=20>"
}
if { $demographics_p == "t" } {
append form_fields "<tr><td>Birthday<td><input name=birthday type=text size=12> (YYYY-MM-DD format must be exact)
<tr><td>Sex<td><input name=sex type=radio value=M CHECKED> Male
<input name=sex type=radio value=F> Female"
}
ns_return 200 text/html "<html>
<head><title>Add Yourself to the Mailing list</title></head>
<body bgcolor=#ffffff text=#000000>
<h2>Add Yourself</h2>
to <a href=\"home.tcl?domain=[ns_urlencode $domain]\">the mailing list</a>
for <a href=\"$backlink\">$backlink_title</a>
<hr>
$blather
<form method=post action=add-2.tcl>
<input type=hidden name=domain value=\"$domain\">
<table>
$form_fields
</table>
<input type=submit value=Submit>
</form>
<hr>
<address><a href=\"mailto:$maintainer_email\">$maintainer_name ($maintainer_email)</a></address>
</body>
</html>
"
Note how the final HTML page is strewn with values from the database,
e.g., $maintainer_email,
$backlink, and
$backlink_title. Thus, it looks to
all intents and purposes like it is part of your friend's service and
you won't be getting e-mail from the confused. See
for an
example.
Figure Caption: Here my mailing list system is being used by another Web
publisher (billg40@tiac.net). If users looked carefully at the location
box, they might notice that they were being bounced from www.tiac.net to
www.greenspun.com after clicking the "join mailing list"
link. Billg40 can keep his Secret Diary of Bill Gates at Tiac, where
they don't run an RDBMS, and yet look just like a high-tech Web
publisher with a staff of programmers and a database administrator.
 A couple of years ago, Olin refused to give Alex (http://philip.greenspun.com/dogs/alex)
a sample off of his plate at brunch. "You're just a dog, Alex,"
Olin said. We pressed Olin as to his reason for feeling superior to
Alex. Olin thought for a few minutes all he could come up with was
"I have a PhD and he doesn't."
A couple of years ago, Olin refused to give Alex (http://philip.greenspun.com/dogs/alex)
a sample off of his plate at brunch. "You're just a dog, Alex,"
Olin said. We pressed Olin as to his reason for feeling superior to
Alex. Olin thought for a few minutes all he could come up with was
"I have a PhD and he doesn't."
Olin demonstrated the practical value of his Carnegie-Mellon computer science degree in 1994 by turning down Jim Clark's offer to become Employee number 3 at a little start-up called Mosaic Communications (grab http://www.netscape.com if you want to see how Jim and Company are doing now). Consequently, his resort to credentialism set off howls of laughter throughout the room.
"Let's see what value society places on your Ph.D., Dr. Shivers," I said. "We'll take both you and Alex to Harvard Square and hang signs around your necks. Alex's sign will read ‘Needs home.' Your sign will read ‘Needs home. Has Ph.D.' Which one of you do you think will have to sit out there longer?"
"Nooooo contest," opined Olin's girlfriend.
 Anyway, Olin clung to his belief that his Ph.D. was worth something
despite the fact that the marketplace was crushing him under a burden of
poverty to correspond to his burden of ignorance of how to build an
RDBMS-backed Web service.
Anyway, Olin clung to his belief that his Ph.D. was worth something
despite the fact that the marketplace was crushing him under a burden of
poverty to correspond to his burden of ignorance of how to build an
RDBMS-backed Web service.
I kept offering to show Olin but he was too busy writing papers for academic journals that even he didn't bother reading. We began to joke that Olin was "afraid to be rich." Then one night Olin came over to my house and said "Let's jack into this World Wide Cybernet thing."
We sat down to build a toy AOLserver/RDBMS-backed birthday reminder system. Sure there are plenty of fancy calendar management systems that incorporate one-time events, recurring events, and reminders. But most of these calendar management programs require you to maintain them on a Macintosh or Windows machine. If you switch from computer to computer then they don't do you much good. We all read our e-mail no matter where we are, so why not build a system that feeds reminders into our e-mailbox? Again, it turns out that there are Web-based calendar management systems that will do just that. But these programs are very complicated. I don't have a job. I don't make appointments. I don't plan in advance. I don't want to invest in learning and using a calendar management program. I just want an email message a week before my friend's birthday so that I can send him a card.
Olin and I sat down at 9:00 pm to build RemindMe. We were finished by midnight. Then we showed the text-only system to Ulla Zang (http://www.ullazang.com) and asked her to do a spiffy graphic design. Now we have a nice public service to offer.
--
-- this table has one row for each person using the system
-- the PRIMARY KEY constraint says that there can't be two
-- rows with the same value in the EMAIL column
--
create table bday_users (
email varchar(100) primary key,
password varchar(100) not null
);
create sequence reminder_id_sequence start with 1;
create table bday_reminders (
reminder_id integer primary key,
email varchar(100) references bday_users,
event_description varchar(400),
event_date date,
remind_week_before_p char(1) check (remind_week_before_p in ('t','f')),
remind_day_before_p char(1) check (remind_day_before_p in ('t','f')),
remind_day_of_p char(1) check (remind_day_of_p in ('t','f')),
last_reminded date
);
create index bday_reminders_idx on bday_reminders(email);
The first item of interest in this data model is the integrity
constraint that values in the email column of
bday_reminders must correspond to values in the
email column of bday_users. That's what
references bday_users tells the database management
system. After a row in bday_reminders is inserted or
updated, the RDBMS will check to make sure that this integrity
constraint is true. If not, the transaction will be aborted. Also,
nobody will be able to delete a row from bday_users if
any rows in bday_reminders still contain the
same e-mail address.
Integrity constraints are critical if you have users typing data into a shell database tool. But here users will only be able to access the RDBMS through our Web pages. Why can't we just write our forms-processing software so that it never allows bad data into the database? Well, we can and we will. But unless you are the rare programmer who always writes perfect code, it is nice to have the RDBMS's integrity constraint system as a last line of defense.
Thomas Jefferson did not say "Eternal vigilance is the price of liberty." That's because he wasn't John Philpot Curran (Irish statesman who never set foot in the United States). Nor did Jefferson say "Eternal sluggishness is the price of integrity." That's because he wasn't an RDBMS programmer.
 You'd think that the most obvious legal transaction would be "add
user to bday_users table." However, I decided to not make that one
of the legal transactions. I don't want a table full of email addresses
for people who aren't really using the system. Thus, it is only legal to
add a user atomically with at least one reminder:
You'd think that the most obvious legal transaction would be "add
user to bday_users table." However, I decided to not make that one
of the legal transactions. I don't want a table full of email addresses
for people who aren't really using the system. Thus, it is only legal to
add a user atomically with at least one reminder:
This transaction inserts the user "philip@greenspun.com" with password "hairysamoyed" and an annual reminder to finish his PhD by June 1st (starting from 1993 when he got his master's). Reminders will be sent a week before, a day before, and the day of. Note that each reminder is assigned a uniquebegin transaction; insert into bday_users (email, password) values ('philip@greenspun.com','hairysamoyed'); insert into bday_reminders (reminder_id, email, event_description, event_date, remind_week_before_p, remind_day_before_p, remind_day_of_p) values (reminder_id_sequence.nextval, 'philip@greenspun.com', 'remember to finish PhD', '1993-06-01', 't', 't', 't'); end transaction;
reminder_id using the
non-standard (but very useful) Oracle sequence generator.
Suppose the user doesn't want to be reminded the day of? That's another legal transaction:
update bday_reminders set remind_day_of_p = 'f' where reminder_id = 5347
A reminder system with only one reminder isn't anything to write home about. We ought to be able to add new events:
A week before December 1st, I'll be reminded to buy shampoo for my Samoyed (he usually requires an entire bottle). I disabled the day before reminder so that's "f". Then I'll be reminded on December 1st itself.insert into bday_reminders (reminder_id, email, event_description, event_date, remind_week_before_p, remind_day_before_p, remind_day_of_p) values (reminder_id_sequence.nextval, 'philip@greenspun.com', 'Wash dog whether he needs it or not', '1997-12-01','t','f','t')
One last legal transaction: deleting a reminder. Suppose that I finish my PhD thesis (to which supposition my friends invariably respond "Suppose the sun falls out of the sky"):
delete from bday_reminders where reminder_id = 5347
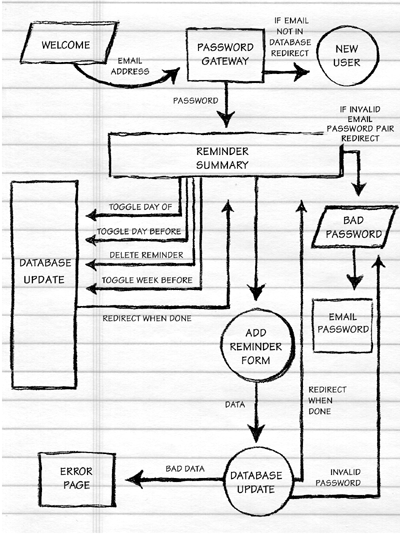
Figure ***: the text-only welcome page, built by me and Olin (no longer available)
Figure ***: (no longer available) the welcome page, designed by Ulla Zang; we saved a lot of time and heartache by completing our interaction design with a text-only site before consulting a graphic designer. Ulla turns out to be one of the few graphic designers I've worked with who is also an excellent interaction designer. Nonetheless, by having finished the programming beforehand, we were able to use Ulla's time to maximum advantage.
Figure ***: the reminders summary page, core of the user interface. Olin and I weren't satisfied with this design but decided to dump the user interface issue onto Ulla.
Figure ***: Ulla's reminders summary page. Much bigger than our text-only version, but also much cleaner. We'll be able to take her simplifications and translate them back into the text-only site as well. [That's another advantage of doing a full text-only site first; you always have something to satisfy the 28.8 modem crowd even if your graphic designer goes wild with huge images.]
set_the_usual_form_variables
# email, password
set db [ns_db gethandle]
if { [database_to_tcl_string $db "select unique upper(password) from bday_users where upper(email) = upper('$QQemail')"] != [string toupper $password] } {
ns_returnredirect "bad-password.tcl?email=[ns_urlencode $email]"
return
}
# if we got here it means that the password checked out OK
# we're going to use this a bunch of times so let's save some work
set emailpassword "email=[ns_urlencode $email]&password=[ns_urlencode $password]"
ns_write "HTTP/1.0 200 OK
MIME-Version: 1.0
Content-Type: text/html
Pragma: no-cache
<html>
<head>
<title>Reminders for $email</title>
</head>
<body bgcolor=#ffffff text=#000000>
<h2>Reminders</h2>
for $email, held by <a href=\"credits.tcl\">RemindMe</a>
<hr>
<ol>
"
set selection [ns_db select $db "select bday_reminders.*, to_char(event_date,'Month DD, YYYY') as formatted_date, to_char(event_date,'MM') as event_month, to_char(event_date,'DD') as event_day
from bday_reminders
where upper(email) = upper('$QQemail')
order by event_month, event_day"]
while {[ns_db getrow $db $selection]} {
set_variables_after_query
ns_write "<li>$event_description : $formatted_date
\[<a href=\"delete.tcl?reminder_id=$reminder_id&$emailpassword\">DELETE</a>\]
<br>
Remind me: "
# it would have been cleaner to think more and come up with
# a general-purpose action.tcl function, but I think it is
# also OK to do what we've done, use a separate .tcl page for
# each kind of action
# for each reminder, we test to see if it is already set,
# then present an appropriate current status hyperlinked to
# a URL that will toggle the state of that reminder
if { $remind_week_before_p == "t" } {
ns_write "\[Week before: <a href=\"week-before-off.tcl?reminder_id=$reminder_id&$emailpassword\">yes</a>\] " } else {
ns_write "\[Week before: <a href=\"week-before-on.tcl?reminder_id=$reminder_id&$emailpassword\">no</a>\] " }
if { $remind_day_before_p == "t" } {
ns_write "\[Day before: <a href=\"day-before-off.tcl?reminder_id=$reminder_id&$emailpassword\">yes</a>\] " } else {
ns_write "\[Day before: <a href=\"day-before-on.tcl?reminder_id=$reminder_id&$emailpassword\">no</a>\] " }
if { $remind_day_of_p == "t" } {
ns_write "\[Day of: <a href=\"day-of-off.tcl?reminder_id=$reminder_id&$emailpassword\">yes</a>\] " } else {
ns_write "\[Day of: <a href=\"day-of-on.tcl?reminder_id=$reminder_id&$emailpassword\">no</a>\] " }
ns_write "\n<p>\n"
}
ns_write "
</ol>
<center>
<a href=\"add-reminder.tcl?$emailpassword\">Add new reminder</a>
</center>
<hr>
<a href=\"mailto:[bday_system_owner]\"><address>[bday_system_owner]</address></a>
</body>
</html>"
Most of the interesting points about this procedure are documented in the comments above. The only thing worth stressing is that this is the meat of the user interface. The links from this page mostly just update the RDBMS and then redirect back to this page. For example, here's week-before-off.tcl:
set_form_variables
# email, password, reminder_id
set db [ns_db gethandle]
# ... password check as in code above ...
ns_db dml $db "update bday_reminders set remind_week_before_p = 'f'
where reminder_id = $reminder_id"
ns_returnredirect "domain-top.tcl?email=[ns_urlencode $email]&password=[ns_urlencode $password]"bday_reminders, then redirects back to the reminder summary
page.
Almost all back ends require that a function be run every day at a set hour. I like to write my back end code using the same tools as the rest of the system. In the old days, I would write the nightly sweeper or whatever as a dynamic Web page. Then I'd use the Unix cron facility to run a shell script every night (the Windows NT equivalent is the At command). The shell script would call htget (a Perl script) to grab this dynamic Web page.
AOLserver, however, has a built-in cron-like function. I prefer to use it rather than an operating system facility because it means less system administration when moving a service from one physical computer to another. Also, my code is portable across operating systems and I won't need to install Perl scripts like htget.
It should be easy:
ns_schedule_daily 5 0 bday_sweep_all
This tells the AOLserver to run the function bday_sweep_all
at 5:00 am every day.
The first and most obvious problem with this statement is that the
server might be down at 5:00 am. If we are careful to define
bday_sweep_all so that it won't send out duplicates, we can
just schedule it for a bunch of times during the day:
ns_schedule_daily 5 0 bday_sweep_all ns_schedule_daily 9 0 bday_sweep_all ns_schedule_daily 13 0 bday_sweep_all
The second problem is an AOLserver bug (my opinion) or feature (Doug
McKee's opinion; he's one of the server's authors): If these statements
are executed multiple times, the function will be multiply
scheduled. For example, if you put these schedule requests in the Tcl
directory that gets sourced on server startup then re-initialize Tcl
five times (to test changes in other code), you will find that
bday_sweep_all is called six times at 5:00 am.
Here's my workaround:
I say that the variablens_share -init {set bday_scheduled_p 0} bday_scheduled_p if { !$bday_scheduled_p } { set bday_scheduled_p 1 ns_schedule_daily -thread 5 0 bday_sweep_all ns_schedule_daily -thread 9 0 bday_sweep_all ns_schedule_daily -thread 13 0 bday_sweep_all }
bday_scheduled_p is to be global
among all the AOLserver threads and intialized to 0. If it has not been
set to 1 yet (!$bday_scheduled_p), I schedule the sweep
at 5:00 am, 9:00 am, and 1:00 pm. Then I set the flag to 1 so that subsequent
loads of this Tcl file won't result in redundant scheduling.
All we have to do now is write the bday_sweep_all
procedure. We can expect the algorithm to be more or less the same for all three
reminder types, so we posit a basic bday_sweep procedure
that takes the reminder type as an argument:
proc bday_sweep_all {} { bday_sweep "day_of" bday_sweep "day_before" bday_sweep "week_before" }
Now we just have to write the sweeper per se:
proc bday_sweep {message_type} {
# message_type can be "week_before", "day_before", "day_of"
switch $message_type {
week_before { set sql_clause "remind_week_before_p = 't'
and to_char(event_date,'MM') = to_char(sysdate + 7, 'MM' )
and to_char(event_date,'DD') = to_char(sysdate + 7, 'DD' )"
set subject_fragment "NEXT WEEK"
set body_fragment "next week"
}
day_before { set sql_clause "remind_day_before_p = 't'
and to_char(event_date,'MM') = to_char (sysdate + 1, 'MM' )
and to_char(event_date,'DD') = to_char (sysdate + 1, 'DD' )"
set subject_fragment "TOMORROW"
set body_fragment "tomorrow"
}
day_of { set sql_clause "remind_day_of_p = 't'
and to_char(event_date,'MM') = to_char (sysdate, 'MM' )
and to_char(event_date,'DD') = to_char (sysdate, 'DD' )"
set subject_fragment "TODAY"
set body_fragment "today"
}
}
set db_connections [ns_db gethandle [philg_server_default_pool] 2]
set db [lindex $db_connections 0]
set db_sub [lindex $db_connections 1]
set email_count 0
set start_stamp [database_to_tcl_string $db "select to_char(sysdate, 'DD-MM-YYYY HH24:MI:SS') from DUAL"]
set selection [ns_db select $db "select reminder_id, bday_reminders.*, to_char(event_date,'Month') as formatted_month, to_char(event_date,'DD, YYYY') as formatted_dayyear
from bday_reminders
where $sql_clause
and (trunc(last_reminded) <> trunc(sysdate) or last_reminded is null)"]
while {[ns_db getrow $db $selection]} {
set_variables_after_query
if [catch { ns_sendmail $email [bday_system_owner] "$event_description is $subject_fragment" "Reminder:
$event_description ([string trim $formatted_month] $formatted_dayyear)
is $body_fragment.
This message brought to you by [bday_system_name].
If you don't want to receive these reminders in the future,
just visit [bday_system_url].
"
} errmsg] {
# failed to send email
ns_log Error "[bday_system_name] failed sending to $email: $errmsg"
} else {
# succeeded sending email, mark the row as reminded
ns_db dml $db_sub "update bday_reminders
set last_reminded = sysdate
where reminder_id = $reminder_id"
incr email_count
}
}
ns_db dml $db "insert into bday_log (message_type, message_count, start_stamp, end_stamp)
values
('$message_type',$email_count, to_date('$start_stamp', 'DD-MM-YYYY HH24:MI:SS'),sysdate)"
# we call these directly because bday_sweep_all calls this fcn
# three times in succession and otherwise NaviServer won't allow
# the ns_db gethandle to go through
ns_db releasehandle $db
ns_db releasehandle $db_sub
}
Okay: When you execute a query, the first thing the kernel does is take note of the time you started the query. As the query progresses through the table, it will look at the SCN ("system change number") of each row, which indicates when it has last been updated. If it finds that the row was updated after the query began, the kernel goes to the rollback buffer to fetch the last value the row held before the query began. So in your example, Connection 1 will not see the update made by Connection 2 if the update is done after the query begins.In fact, even after the query finishes and you start another, it still won't see the change...not until you explicitly commit the update. (I shouldn't say "explicitly" since closing the connection cleanly will also perform a commit.) But even if you commit while the query is running, it still won't get the new value. However, the next time you query, it will catch the change.
But wait, there's more. Let's say you don't do a "commit" in Connection 2, but you enter the same query as before, this time in Connection 2. While that's running, you also run the query in Connection 1. The results will differ. Why? Because the query running in Connection 2 knows you've made an update, and sees those SCNs rather than the ones stored in the permanent table structure. [Technically: before a commit, the results of a write operation are stored in the ITL (Interested Transaction Layer). A session has access to the portion of those results performed in that session only; these operations are "presumably committed" for the purposes of whatever you do in that session. It cannot, however, see anything in other sessions, which is why Connection 1 has no clue what you've done until you truly commit it.] This illustrates one of the challenges of concurrent programming with databases -- Lesson: Always commit your changes as soon as you know they're permanent. (Corollary: Always have frequent backups for those plentiful occasions when they weren't and aren't reversible.)
Regarding locks [a subject which I know for a fact varies among database vendors], Connection 1 will not lock the table, unless the person executing the query has explicitly done so beforehand by doing "select * from table_name for update". If so, it would be released after an explicit "commit" is typed, and Connection 2 would wait and/or time out while the lock is held.
Most likely, you would not want to lock an entire table for a query. The only reason I can dream of doing this is if: 1) you need to run a very long query (many hours), 2) there are tons of transactions going on simultaneously, 3) those transactions are less important than the query results, and 4) you have a very small amount of rollback space. Remember that point at which it finds a newer SCN and fetches the old value from the rollback? If the rollback doesn't go back far enough, the query errors out with an ORA-1555 : snapshot too old" error. So as long as the entire table isn't locked, and no other connections are locking the rows you need to update, connection 2 will do its update right away.
When Connection 2 does update, it will either lock the entire table or just the row it is trying to update, depending on the database's system and session parameters, e.g. if something like "ROW_LOCKING=ALWAYS" is in your oracle.ini file. I think the default is to lock the table, but don't quote me on that (it would be silly if we did, since row locking is a big thing for Oracle.)
The question of yours regarding the SQL standard: That I don't know. I've never read the ANSI standards for SQL or SQL92, but I do not believe there are any rules regarding the behavior of concurrent sessions. If there is, though, I'm fairly confident we're doing what it says. (If we weren't, we'd be fixing it, and I've heard of no intentions to do so.)
 One of my motivations for building the fancy software described in the community chapter was the difficulty of
moderating the Q&A forum for photo.net. With about 10,000 participants,
deleting duplicate postings and uninteresting threads was time-consuming
but bearable. One day in 1997, Martin Tai showed up. He contributed
some useful information about black and white film development and the
Minox spy cameras. He also added some eyebrow-raising statements such
as that a print from a Minox was as good as that from a 4x5 inch view
camera in 8x10 inch enlargements. Since a Minox negative is less than
one tenth the area of a standard 35mm negative, which is in turn
laughably poor quality compared to what you get out of a view camera,
this generated some skepticism. Martin pointed to some Web sites
displaying Minox photos that allegedly proved his point, but to my eyes
you could clearly see the failure in lens and film resolution right on
screen.
One of my motivations for building the fancy software described in the community chapter was the difficulty of
moderating the Q&A forum for photo.net. With about 10,000 participants,
deleting duplicate postings and uninteresting threads was time-consuming
but bearable. One day in 1997, Martin Tai showed up. He contributed
some useful information about black and white film development and the
Minox spy cameras. He also added some eyebrow-raising statements such
as that a print from a Minox was as good as that from a 4x5 inch view
camera in 8x10 inch enlargements. Since a Minox negative is less than
one tenth the area of a standard 35mm negative, which is in turn
laughably poor quality compared to what you get out of a view camera,
this generated some skepticism. Martin pointed to some Web sites
displaying Minox photos that allegedly proved his point, but to my eyes
you could clearly see the failure in lens and film resolution right on
screen.
Personally I didn't mind having Martin as a community member despite his eccentric belief in the quality of the Minox's 8x11mm negatives. However, he'd apparently previously annoyed folks in rec.photo.* (USENET) exchanges and even the slightest error on Martin's part provoked a volley of vitriolic responses from other photo.net readers. Every day I'd have to go in and clear out 50 postings plus respond to private e-mail complaints.
My forums at the time were backed by the Illustra relational database management system, the child of some self-professed computer science geniuses at UC Berkeley. They spent a lot of time writing papers for academic journals about how stupid the engineers at Oracle were. Indeed, Illustra did quite a few things that Oracle could not. For one user at a time. If you wanted to update an Illustra row, you had to wait for all the readers to stop reading. If you wanted to read from an Illustra row, you had to wait for all the writers to stop writing. The bottom line was that, as soon as you had more than one person using Illustra, the system tended to deadlock. Under the best of circumstances, users posting to the forum would get a page saying
Under heavy usage, the users would seeplease wait while we try to insert your message ..... message inserted.
please wait while we try to insert your message .. *** 60 second pause *** ... deadlock, transaction aborted. Please hit Reload in five or ten minutes.
I felt humiliated by the situation but for a variety of annoying reasons, it was taking me months to move my services to Oracle. Then it hit me: Sometimes a system that is 95 percent reliable is better than a system that is 100 percent reliable. If Martin was accustomed to seeing the system fail 5 percent of the time, he wouldn't be suspicious if it started failing all of the time. So I reprogrammed my application to look for the presence of "Martin Tai" in the name or message body fields of a posting. Then Martin, or anyone wanting to flame him, would get a program that did
ns_write "please wait while we try to insert your message ..."
ns_sleep 60
ns_write "... deadlock, transaction aborted. Please hit Reload
in five or ten minutes."
The result? Martin got frustrated and went away. Since I'd never served him a "you've been shut out of this community" message, he didn't get angry with me. Presumably inured by Microsoft to a world in which computers seldom work as advertised, he just assumed that photo.net traffic had grown enough to completely tip Illustra over into continuous deadlock.
I've used this trick a few more times in the photo.net forums with users who wouldn't take gentle suggestions from the moderators. Even though I've subsequently converted to Oracle, so that message insertion is 100 percent reliable and takes one-tenth of a second, no user has ever suspected foul play when presented with a "database error" page.
The general rule to be extracted here is to take advantage of the world that Microsoft has created. Don't tell users that you hate them. Just program your server so that it can pretend to be broken.
 I wish that I could say it was my passion for distributing knowledge
that inspired me to construct on-line quiz software. However, the truth
is more complex. In fact, it is sometimes brutal. In The Game, at
http://philip.greenspun.com/dating/,
the truth is always brutal.
I wish that I could say it was my passion for distributing knowledge
that inspired me to construct on-line quiz software. However, the truth
is more complex. In fact, it is sometimes brutal. In The Game, at
http://philip.greenspun.com/dating/,
the truth is always brutal.
Conceived as an extension of my systematic five-year Web-based program
to demonstrate the futility of graduate school in science and engineering
(http://philip.greenspun.com/careers/),
The Game puts the user in a heterosexual dating situation:
.
What are the challenges in building software like this? There is the obvious one of making it easy to add quizzes merely by adding rows to relational database tables. A more interesting challenge is presented by the fact that the Web is inherently stateless. Users expect to be able to back up or reload at any time. However, they shouldn't thereby be able to improve their score. There are probably clever cryptographic ways to accomplish this. But if I paid $100,000 for an Oracle license, I shouldn't have to be clever. So this software, which we call ArsDigita Quizze, keeps updating a row in the database with the quiz-taker's history.
Here are the central features of ArsDigita Quizze:

Answers point only to questions:create table quizzes ( quiz_id integer primary key, title varchar(100), first_question_id integer not null, min_image_number integer, max_image_number integer, -- the sum of all the plays total_score integer default 0, -- how many plays (so we can compute the average) total_trials integer default 0 ); create table questions ( question_id integer not null primary key, -- this will be NULL for the last question next_question_id integer references questions, quiz_id integer not null references quizzes, preamble varchar(4000), text varchar(4000) not null );
Note that each answer contains acreate table answers ( answer_id integer primary key, question_id integer not null references questions, text varchar(4000) not null, score_delta number not null, responses integer default 0 );
score_delta column to
indicate how much the player's score should be adjusted in the event
that it is chosen, plus a responses column for tallying the
number of players who've chosen it.
Each play of the game gets a row in the players table. The
same person playing four times results in four row insertions. Note
that we're using the Oracle sequence generator to create unique
player_id values.
The interesting column here iscreate sequence player_id_sequence; create table players ( player_id integer not null primary key, start_time date, quiz_id integer not null references quizzes, questions_answered varchar(4000), score number default 15 );
questions_answered. We keep
a space-separated list of all the question_ids that the user has
answered, e.g., "23 45 67 81". This facilitates checking for
already-answered question in Tcl, which stores lists as space-separated
tokens in a string.
quiz_id:
set_form_variables # quiz_id is now defined set db [ns_db gethandle] set player_id [database_to_tcl_string $db "select player_id_sequence.nextval from dual"] ns_db dml $db "insert into players (player_id, start_time, quiz_id) values ($player_id, sysdate, $quiz_id)" ns_write "HTTP/1.0 302 Found Location: question.tcl MIME-Version: 1.0 Set-Cookie: player_id=expired; path=/; expires=Fri, 01-Jan-1990 01:00:00 GMT Set-Cookie: player_id=$player_id; path=/; You should not be seeing this! "
 The first thing to note is that we go to Oracle to get the next
The first thing to note is that we go to Oracle to get the next
player_id value before doing the INSERT. We do this
because the Tcl script needs to have the value to put into the
Set-Cookie header. The next thing to note is that this
page isn't intended to be read by the user; it issues a 302
Redirect instructing the user's browser to visit question.tcl.
AOLserver has a convenient ns_returnredirect API call that
will write out a similar collection of bytes, but we also want to write
the Set-Cookie headers. The first Set-Cookie
instructs the browser to delete any previous player_id
cookie value by giving an expiration date in the past (see
http://home.netscape.com/newsref/std/cookie_spec.html
for where this is promulgated as the preferred method of deleting a
cookie). The second Set-Cookie instructs the browser to
send our server back a player_id header on every subsequent
page request, regardless of where on the server the page is
(path=/). Because we did not specify an expiration date,
the cookie will expire when the user quits Netscape Navigator.
The blank lines after the last header are very important and part of the HTTP standard. Browsers are usually relaxed about such things, but Web proxies are not. If you terminate your script with the last header, you'll find that users behind corporate firewalls generally can't use your service. I try to remember to put in a couple of blank lines plus some text that I don't expect the user to see.
set_form_variables 0
# answer_id may or may not have been defined, depending on
# whether this is the user's first question
set headers [ns_conn headers $conn]
set cookie [ns_set get $headers Cookie]
if { ![regexp {player_id=([^;]+)} $cookie {} player_id] } {
ns_return 200 text/html "no cookie :-( "
return
}
# we have player_id from the cookie header
set db [ns_db gethandle]
set selection [ns_db 0or1row $db "select * from players where player_id = $player_id"]
if { $selection == "" } {
ns_return 200 text/html "no entry in the RDBMS :-( "
return
}
# we have a row from the database, now turn the columns into Tcl local
# variables
set_variables_after_query
# going to use quiz_id, questions_answered, score
# process answer to previous question
set reanswering_note ""
if { [info exists answer_id] } {
# we only know the answer_id; we have to ask Oracle to
# which question this answer corresponds
set selection [ns_db 1row $db "select question_id as corresponding_question_id, score_delta from answers where answer_id = $answer_id"]
set_variables_after_query
if { [lsearch $questions_answered $corresponding_question_id] == -1 } {
# the current question is not among those previously answered
set current_score [expr $score + $score_delta]
# record the question as answered by this player
ns_db dml $db "update players
set questions_answered = '[lappend questions_answered $corresponding_question_id]',
score = $current_score
where player_id = $player_id"
# update the statistical tally for this answer
ns_db dml $db "update answers set responses = responses + 1 where answer_id = $answer_id"
set next_question_id [database_to_tcl_string $db "select next_question_id from questions where question_id = $corresponding_question_id"]
} else {
# re-answering a question
set next_question_id [database_to_tcl_string $db "select next_question_id from questions where question_id = $corresponding_question_id"]
set current_score $score
set reanswering_note "<p>(not updated because you already answered the previous question)"
}
} else {
# not answering a question (presumably this is the first iteration)
# set score according to what was in the database (presumably the
# default value of 15)
set current_score $score
if { $questions_answered == "" } {
# we're on the very first question
set next_question_id [database_to_tcl_string $db "select first_question_id from quizzes where quiz_id = $quiz_id"]
} else {
# we will only get to this code if the user backs up to the very
# first question.tcl (with no form vars)
set last_question_id [lindex $questions_answered [expr [llength $questions_answered]-1]]
set next_question_id [database_to_tcl_string $db "select next_question_id from questions where question_id = $last_question_id"]
}
}
if { $next_question_id == "" } {
# there are no more questions and we've recorded their
# answer and updated their score, so redirect them to the
# "thanks for playing" page
ns_returnredirect final-score.tcl?reason=no_more_questions
return
}
# prepare to display the next question, finding it in the database
# by using the next_question_id that we previously looked up
# we have to JOIN with the quizzes table in order to get the minimum
# and maximum image numbers. Logically this should simply be a separate
# query (to the quiz table alone) but realistically it is much faster to
# only go to the Oracle kernel once.
set selection [ns_db 1row $db "select preamble, text as question_text, min_image_number, max_image_number
from questions, quizzes
where question_id = $next_question_id
and questions.quiz_id = quizzes.quiz_id"]
set_variables_after_query
# we know the max possible score now, so let's check to see if this
# guy should be bounced
if { $current_score >= $max_image_number } {
ns_returnredirect final-score.tcl?reason=player_won
return
}
# we assume that we have integer images in the /images/**quiz_id**/ dir named
# 0.2.jpg through 30.2.jpg (these will be the 2nd PhotoCD resolution,
# i.e, 256x384
# each image will be a hyperlink to bigger.tcl?quiz_id=n&image_number=m
# the bigger.tcl file will display the .3 PhotoCD res and offer a hyperlink
# to the .4 res.
# < min we round up to min; > max and they should not have gotten here
# (if statement above) but we handle the case anyway so we don't ever
# risk showing a broken image icon
set image_number [expr round($current_score)]
if { $image_number < $min_image_number } {
set image_number $min_image_number
}
if { $image_number > $max_image_number } {
set image_number $max_image_number
}
if { $preamble == "" } {
set full_blurb $question_text
} else {
set full_blurb "$preamble\n<br><br>\n$question_text"
}
# return standard HTTP 200 headers but with a no-cache directive
# so that the user's browser doesn't just pull a page from its
# cache (with an old score) if he goes back
ns_write "HTTP/1.0 200 OK
MIME-Version: 1.0
Content-Type: text/html
pragma: no-cache
<html>
<head>
<title>$question_text</title>
</head>
<body bgcolor=#ffffff text=#000000>
<center>
<a target=bigpicture href=\"bigger.tcl?quiz_id=$quiz_id&image_number=$image_number\">
<img border=0 src=\"images/$quiz_id/$image_number.2.jpg\">
</a>
<h3>$full_blurb</h3>
</center>
<blockquote>
<ul>
"
# note that we wrote all the stuff above so that the user would have
# something to look at before we hit Oracle again (to get all the
# possible answers)
set selection [ns_db select $db "select answer_id, text as answer_text
from answers
where question_id = $next_question_id"]
while { [ns_db getrow $db $selection] } {
set_variables_after_query
ns_write "<p><li><a href=\"question.tcl?answer_id=$answer_id\">$answer_text</a>\n"
}
ns_write "
</ul>
</blockquote>
<center>
<h3>Your current score: $current_score</h3>
$reanswering_note
</center>
<hr>
<a href=index.tcl>The Game</a>
</body>
</html>"
 Nearly all of the interesting ideas in the above script are covered in
the comments. Note, however, that we never put the answer
Nearly all of the interesting ideas in the above script are covered in
the comments. Note, however, that we never put the answer
score_delta's in hidden variables in the outgoing page.
The scoring of the quiz remains secret from users who "view source" with
their browsers. Another thing to observe is the extent to which we are
hammering Oracle. On an average page load we
Lesson: Write your code as cleanly as possible; use the database where elegant; optimize if the performance isn't adequate.
).
How is this done? First we query the quizzes table to find the first
question's id:
Then we use the magic Oracle CONNECT BY clause to pull out the linked list of questions in one query:select title, first_question_id from quizzes where quiz_id = $quiz_id;
In order to do the percentage math in SQL rather than Tcl, we have to first query the answers table to get the total responses to a particular question:select question_id, text as question_text from questions where quiz_id = $quiz_id start with question_id = $first_question_id connect by question_id = PRIOR next_question_id
Now we can grab the rows that you see in the report:select sum(responses) as total_responses from answers where question_id = $question_id
select text as answer_text, responses, score_delta,
round((responses/$total_responses)*100) as percentage
from answers
where question_id = $question_id
We will be doing the last two queries for every question.
Note that CONNECT BY is not part of standard SQL and that to make it run fast on a large table, you will need to create two concatenated indices:
See Oracle 8: The Complete Reference (Koch and Loney 1997; Osborne) for more detail on CONNECT BY. If you're not using Oracle, check under "tree extensions" to see what your RDBMS vendor has provided.create index questions_idx1 on questions(question_id,next_question_id); create index questions_idx2 on questions(next_question_id,question_id);
Oh yes, the name. We took the name "Brutal Truth Industries" from the inspired Cement Cuddlers piece reprinted at http://philip.greenspun.com/humor/cement-cuddlers.
 For those cases where the cure is worse than the disease, my friends and
I built the Uptime service (now defunct). Users type in their email
address and a URL. The Uptime server tries to grab the URL every 15 or
20 minutes and sends them email if their server doesn't return
"success".
For those cases where the cure is worse than the disease, my friends and
I built the Uptime service (now defunct). Users type in their email
address and a URL. The Uptime server tries to grab the URL every 15 or
20 minutes and sends them email if their server doesn't return
"success".
It sounds absurdly simple but after a few minutes you realize that there are some tough challenges:
Remarkably simple, eh? Note that a server's reachableness is entirely encapsulated in thecreate table uptime_urls ( monitor_id integer not null primary key, url varchar(200) not null, name varchar(100) not null, email varchar(100) not null, password varchar(30) not null, homepage_url varchar(200), first_monitored date, -- the following are for people who have beepers -- and need a special tag or something in the subject custom_subject varchar(4000), custom_body varchar(4000), -- we always send email when the server is down, we can -- also send email when the server comes back up notification_mode varchar(30), -- 'down_then_up', 'periodic' -- these two are only used when notification_mode is 'periodic' notification_interval_hours integer default 2, last_notification date, -- if this is NULL, it means that we've sent a BACK UP notification time_when_first_unreachable date, unique(url,email) ); create table uptime_log ( monitor_id not null references uptime_urls, event_time date, event_description varchar(100) ); create index uptime_log_idx on uptime_log (monitor_id);
time_when_first_unreachable column. We
set this to sysdate when we notice that a site is newly
unreachable. We set this to NULL when we are able to
successfully grab the URL again. Note that for periodic notification,
the state of our having notified a user is entirely encapsulated in the
last_notification column. Note finally that the
uptime_log table has no primary key. Events are merely
logged with the expectation that they will never be deleted or updated.
In order to make reporting for a particular URL fast, we define an index
on the table by monitor_id.
The first challenge in building a free service is designing forms that are self-explanatory and yet powerful enough to let users take advantage of all the system's capabilities. See ***link no longer available*** for what I think is a successful form (about 500 people have registered to use the service and hardly anyone has sent email to clear up confusion). Basically the goal is to quickly separate those who are having e-mail sent to a pager from those who are receiving e-mail personally. The pager crowd can later edit their monitor to add a custom subject or body.
Privacy has presented an interesting dilemma. If my server is down all of the time, do I want the rest of the world to know? Probably not. But what if I have good uptime and want to prove it to skeptics? Then I want to be able to direct these skeptics to a trusted source (i.e., Uptime) and let them see the record for themselves. Although we still use the password to authenticate people who want to delete or edit monitors, I decided to make Uptime event records public. Why? Anyone on the Internet can monitor an arbitrary URL. Hence there is no practical way for a site to hide its downtime. For example, joe_nerd@stanford.edu can spent five minutes with AOLserver or Web Client Programming (Wong 1997; O'Reilly) to build a monitor for http://www.ai.mit.edu and then release the results.
With this kind of openness, what kinds of users has the system attracted? My favorite is Online Privacy (http://www.privacy.nb.ca/), "a non-profit group of computer professionals who intend to educate and help the general public preserve their personal privacy while online".
Scanning the rest of the list, I'm gratified to see that, after more than one year of operation, only one of ArsDigita's customers has signed up to monitor a site that we built! Also, though I built Uptime with the expectation that sysadmins would be the primary users, as of July 12, 1998 six GeoCities "customers" are using my service. I'm not really sure what they do if Uptime reports that their site is unreachable. Do they complain to GeoCities that they aren't getting their money's worth?
I'd expected most of the folks using Uptime to be operators of complex database-backed Web services. Thus the URL being monitored would be some kind of script that tried to connect to the RDBMS and would report "success" if everything was fine. In fact, as I scan through ***link no longer available***, I note that many of the URLs monitored are plain vanilla .txt files (this is true even for the big companies using the service, e.g., ARCO, LSI Logic, Metropolitan Opera, MGM, Seagate, and the United Way).
# tell AOLserver to run uptime_monitor_once every 20 minutes
# the -thread option instructs AOLserver to spawn a new thread
# for this procedure, i.e., that the procedure probably won't
# return quickly
ns_schedule_proc -thread 1200 uptime_monitor_once
# tell AOLserver to run uptime_monitor_stale every night at 11:45
ns_schedule_daily -thread 23 45 uptime_monitor_stale
proc uptime_monitor_once {} {
set db [ns_db gethandle]
set monitor_ids [database_to_tcl_list $db "select monitor_id
from uptime_urls
where uptime_stale_p(time_when_first_unreachable) = 'f'"]
ns_log Notice "Uptime starting to test [llength $monitor_ids] URLs"
uptime_monitor_list_of_ids $db $monitor_ids
ns_log Notice "Uptime finished sweeping."
}
proc uptime_monitor_stale {} {
set db [ns_db gethandle]
set monitor_ids [database_to_tcl_list $db "select monitor_id
from uptime_urls
where uptime_stale_p(time_when_first_unreachable) = 't'"]
ns_log Notice "Uptime working on the stale URLs ([llength $monitor_ids] of them)"
uptime_monitor_list_of_ids $db $monitor_ids
ns_log Notice "Uptime finished with the stale URLs."
}
Note that these procedures both rely on
uptime_monitor_list_of_ids to do all the real work, passing
it a database connection and a list of keys into the
uptime_urls table. Note further that both write something
into the AOLserver error log when they start and stop. This makes it
easy to look at the log and find out how long sweeps are taking.
The use of uptime_stale_p bears some explaining. This is a
PL/SQL function that takes in a date and returns true or false (Oracle
lacks the Boolean data type hence these are presented by the letters "t"
and "f"). The concept of a URL having gone stale is sufficiently
fundamental to the system that I wanted to make sure it was consistent
across all the monitoring scripts, reporting scripts, etc. In fact, it
would have been easier to simply include
in the query than putwhere time_when_first_unreachable is null or time_when_first_unreachable > (sysdate - 10)
create or replace function uptime_stale_p (time_when_first_unreachable IN date) return varchar
is
begin
IF time_when_first_unreachable is null THEN
return 'f';
ELSIF time_when_first_unreachable > (sysdate - 10) THEN
return 'f';
ELSE
return 't';
END IF;
end;
in the data-model.sql file. However, I personally get a warm and fuzzy
feeling knowing that all of my Tcl scripts will rely on this procedure
to determine staleness (in this case we've set it for 10 days).
What's under the hood of that uptime_monitor_list_of_ids
procedure?
proc uptime_monitor_list_of_ids {db monitor_ids} {
foreach monitor_id $monitor_ids {
set selection [ns_db 0or1row $db "SELECT uu.*,
to_char(time_when_first_unreachable,'YYYY-MM-DD HH24:MI:SS') as
full_unreachable_time,
to_char(sysdate,'YYYY-MM-DD HH24:MI:SS') as full_sysdate,
round((sysdate - time_when_first_unreachable)*60*24) as n_minutes_downtime
FROM uptime_urls uu
WHERE monitor_id = $monitor_id"]
if { $selection == "" } {
# this row got deleted from the database while we were
# running our script; this presumably
# happens very rarely (user chooses to delete his monitor)
# but we must handle it for cleanliness
# jump to next iteration
continue
}
# there was a row in the database
set_variables_after_query
# now url, email, a bunch of other stuff are set
ns_log Notice "Uptime testing $url for $email ..."
# we do the ns_httpget inside a Tcl catch because we don't
# want one URL that raises a Tcl error to make the sweep halt
# for everyone else; ns_httpget wil raise an error when a server
# doesn't respond, when a URL is badly formed, e.g., "htttp" or
# "https" (doesn't handle SSL), etc.
if [catch {set grabbed_text [ns_httpget $url]} errmsg] {
ns_log Notice "Uptime failed to reach $url"
set grabbed_text "GETURL failed"
# let's try once more before raising the alarm
if [catch {set grabbed_text [ns_httpget $url]} errmsg] {
ns_log Notice "Uptime failed to reach $url (second attempt)"
set grabbed_text "GETURL failed"
}
} else {
ns_log Notice "Uptime grabbed something from $url"
}
if { [regexp -nocase "success" $grabbed_text] } {
# we got it
if { $time_when_first_unreachable != "" } {
# we have the URL on record as having been dead
ns_db dml $db "update uptime_urls
set time_when_first_unreachable = NULL
where monitor_id = $monitor_id"
ns_db dml $db "insert into uptime_log
(monitor_id, event_time, event_description)
values
($monitor_id, sysdate, 'back_up')"
if { $notification_mode == "down_then_up" } {
ns_sendmail $email [uptime_system_owner] "$url back up" "$url returned \"success\".
It was last reached by [uptime_system_name] at $full_unreachable_time ([uptime_system_timezone]).
Currently our Oracle database thinks it is $full_sysdate.
In other words, your server has been unreachable for approximately
$n_minutes_downtime minutes.
Does this mean your server was down? No. Our server could have lost ITS
network connection. Or there could have been some problem on the
wider Internet.
Does this mean your server was actually unreachable for all of those
minutes? No. We only sweep every 15 minutes or so
"
}
}
} else {
# we did NOT successfully reach the URL (or the page we got
# back did not contain the word "success")
if { $time_when_first_unreachable == "" } {
# this is the first time we couldn't get it
ns_db dml $db "update uptime_urls
set time_when_first_unreachable = sysdate,
last_notification = sysdate
where monitor_id = $monitor_id"
ns_db dml $db "insert into uptime_log
(monitor_id, event_time, event_description)
values
($monitor_id, sysdate, 'down')"
set subject "$url is unreachable"
set body "[uptime_system_name] cannot reach $url.
You may want to check your server.
Does this mean that your server is down? No. But as of $full_sysdate
([uptime_system_timezone]), our server is having trouble reaching it.
Oh yes, if you are annoyed by this message and want to desubscribe
from [uptime_system_name], visit
[uptime_url_base]delete.tcl?monitor_id=$monitor_id
"
if { ![string match $custom_subject ""] } {
set subject $custom_subject
}
if { ![string match $custom_body ""] } {
set body $custom_body
}
ns_sendmail $email [uptime_system_owner] $subject $body
} else {
# site is unreachable, but we already knew that
if { $notification_mode == "periodic" && [database_to_tcl_string $db "select count(*)
from uptime_urls
where (last_notification + notification_interval_hours/24) < sysdate
and monitor_id=$monitor_id"] == 1 } {
# we are supposed to notify periodically and our time
# has come
# update the database first so that we don't run wild
ns_db dml $db "update uptime_urls set last_notification = sysdate
where monitor_id=$monitor_id"
set subject "$url is unreachable"
set body "[uptime_system_name] cannot reach $url.
You may want to check your server.
Oh yes, if you are annoyed by this message and want to desubscribe
to [uptime_system_name], visit
[uptime_url_base]delete.tcl?monitor_id=$monitor_id
"
if { ![string match $custom_subject ""] } {
set subject $custom_subject
}
if { ![string match $custom_body ""] } {
set body $custom_body
}
ns_sendmail $email [uptime_system_owner] $subject $body
}
}
}
}
}
ns_schedule_daily -thread 23 30 uptime_notify_system_owner
proc uptime_notify_system_owner {} {
set db [ns_db gethandle]
set total_entries [database_to_tcl_string $db "select count(*)
from uptime_log
where trunc(event_time) = trunc(sysdate)"]
ns_sendmail uptime@arsdigita.com uptime@arsdigita.com "Uptime sent $total_entries messages" ""
}
The one odd thing to note about this query is the use of
trunc. In most Oracle installations, if you ask Oracle to
print out the date, you'll get precision down to the day:
However, Oracle internally records precision down to the second. This makes naive comparisons fail:SQL> select sysdate from dual; SYSDATE ---------- 1998-07-12
create table test_dates (
the_value varchar(20),
the_date date
);
insert into test_dates values ('happy',sysdate);
insert into test_dates values ('happy',sysdate);
insert into test_dates values ('joy',sysdate);
insert into test_dates values ('joy',sysdate);
*** brief pause ***
SQL> select * from test_dates where the_date = sysdate;
no rows selected
We didn't get any rows because none matched down to the second. Are we
stuck? No. We can rely on the fact that Oracle stores dates as
numbers:
An arguably cleaner approach is to useSQL> select * from test_dates where trunc(the_date) = trunc(sysdate); THE_VALUE THE_DATE -------------------- ---------- happy 1998-07-12 happy 1998-07-12 joy 1998-07-12 joy 1998-07-12
to_char:
select * from test_dates where to_char(the_date,'YYYY-MM-DD') = to_char(sysdate,'YYYY-MM-DD');
Note: For more about Oracle and dating, see http://www.photo.net/wtr/oracle-tips.html.
 As of July 12, 1998, Uptime had 55,486 server-days of monitoring under
its belt. It had observed 10,760 unreachability incidents that weren't
corrected by the next sweep. So from a particular browser's point of
view, the average Web site would appear to be unreachable 5.8
times a month.
As of July 12, 1998, Uptime had 55,486 server-days of monitoring under
its belt. It had observed 10,760 unreachability incidents that weren't
corrected by the next sweep. So from a particular browser's point of
view, the average Web site would appear to be unreachable 5.8
times a month.
What are the sources of these problems? If you scan through ***link no
longer available***
network connectivity doesn't seem to be the overwhelming determining
factor. The machines inside MIT Net (where the Uptime server resides)
should be at the top of the list. Yet a little playing around with
traceroute shows that the top machines are in Houston,
Minnesota, New York, etc. Some of the most reliably reachable servers
seem to be BBN Planet customers (MIT's ISP) but others require hops to
other backbones.
ISP diligence seems to be a factor. Many of the best servers are operated by Mindspring, for example. It looks like even a diligent ISP cannot conquer technology, however. For example, my main static site seems to have suffered 1.6 outages per month. It relies only on HP-UX. But db.photo.net is down at 7.2 outages per month. It relies on Solaris, Illustra (for all of the monitored period), and Oracle 8 (for some of the monitored period).
The RDBMS seems to be implicated in many of the worst performing sites in the Uptime service. Nearly in last place are www.greenspun.com and lavsa.com, both hosted at America Online's Primehost facility. The folks at Primehost run the Illustra RDBMS and they stop answering tech support calls at 9:00 pm eastern time. This combination is apparently capable of producing between 27 and 35 outages a month.
After computing these statistics, I moved greenspun.com to MIT and an Oracle backend.
 As with my community software, the Achilles heel of a service like this
is bouncing email. Without some kind of automated system for absorbing
bounced notifications and eventually deleting those folks from the
database of users, operating Uptime eventually will become a living hell
for the maintainer (i.e., me and my friends). Looking around Yahoo I
found that there are some commercial companies
(e.g., http://www.netmechanic.com
and
http://www.redalert.com)
offering Uptime-like services. They charge $10 to $20 a month. Now I know
why! What I'd love to do is tell people that Uptime is a free service
but take their credit card number on condition that I get to feed it
into ArsDigita Shoppe (see the ecommerce
chapter) if I'm forced to edit or delete their monitor.
As with my community software, the Achilles heel of a service like this
is bouncing email. Without some kind of automated system for absorbing
bounced notifications and eventually deleting those folks from the
database of users, operating Uptime eventually will become a living hell
for the maintainer (i.e., me and my friends). Looking around Yahoo I
found that there are some commercial companies
(e.g., http://www.netmechanic.com
and
http://www.redalert.com)
offering Uptime-like services. They charge $10 to $20 a month. Now I know
why! What I'd love to do is tell people that Uptime is a free service
but take their credit card number on condition that I get to feed it
into ArsDigita Shoppe (see the ecommerce
chapter) if I'm forced to edit or delete their monitor.