
Chapter 9: User Tracking
by Philip Greenspun, part of Philip and Alex's Guide to Web PublishingRevised (lightly) July 2003
|
|
Chapter 9: User Trackingby Philip Greenspun, part of Philip and Alex's Guide to Web PublishingRevised (lightly) July 2003 |
 This chapter discusses what we can infer from monitoring user activity
on the Web, how to use that information to personalize a user's Web
experience, and whether it wouldn't be better to push some of the
responsibility for personalization onto the client.
This chapter discusses what we can infer from monitoring user activity
on the Web, how to use that information to personalize a user's Web
experience, and whether it wouldn't be better to push some of the
responsibility for personalization onto the client.
Here are some examples of starting points:
Let's take these one at a time.
The first field is the name of the client machine. It looks like someone connected to the Internet via PSI in Providence, Rhode Island. The photo.net Web server program, AOLserver, has written the date and time of the connection and then the request line that the user's browser sent: "GET /sammantha/travels-withsammantha.html HTTP/1.0". This says "Get me the file named /sammantha/travels-withsammantha.html and return it to me via the HTTP/1.0 protocol." This is close to /samantha/travels-with-samantha.html but not close enough for the Unix file system, which tells AOLserver that it can't find the file. AOLserver returns a "404 File Not Found" message to the user. We see the 404 status code in the log file and then the number of bytes sent (170). The dash after the 170 normally contains the value of the "referer header" (yes, it is misspelled in the standard), indicating the page from which the user clicked. In this case that field is empty, meaning either that the user has typed in the URL directly from "Open Location" or that the user's browser did not supply a referer header. AOLserver logs the user-agent header so we know that this person is using Netscape (Mozilla) 3.0 on the Macintosh. Netscape 3.0 definitely does supply the referer header. So unless someone can drive down to Providence and teach this user how to spell, he is out of luck.ip248.providence.ri.pub-ip.psi.net - - [28/Jan/1997:12:35:54 -0500] "GET /sammantha/travels-withsammantha.html HTTP/1.0" 404 170 - "Mozilla/3.0 (Macintosh; I; 68K)"
If you're using Apache as a Web server program you might be interested in trying Alexei Kosut's mod_speling module that attempts to correct user spelling/capitalization errors and redirects appropriately.
Moving on to the next 404 . . .
Here's a user from CompuServe. This person is asking for a review of the Canon EOS 70-200/2.8L lens and gets the same 404 and 170 bytes. But this user's referer header was "http://www.cmpsolv.com/photozone/easy.htm". There is a link from this page to a non-existent file on the photo.net server. Does that mean that the photozone folks at cmpsolv.com were losers? Actually it means that I was a loser at least twice. First for not thinking carefully enough about file system organization and second for not adding a redirect when the lens review was moved (the review is currently at its third location: http://www.photo.net/canon/70-200).hd07-097.compuserve.com - - [28/Jan/1997:12:42:53 -0500] "GET /philg/photo/canon-70-200.html HTTP/1.0" 404 170 http://www.cmpsolv.com/photozone/easy.htm "Mozilla/2.0 (compatible; MSIE 2.1; Windows 3.1)"
An interesting side note about this server log entry is the user-agent header: "Mozilla/2.0 (compatible; MSIE 2.1; Windows 3.1)". The first part says "I'm Netscape 2.0." The second part says "I'm Microsoft Internet Explorer 2.1." In 1995, Web publishers with too much time and money programmed their services to deliver a frames-based site to Netscape 2.0 Achievers and a non-frames site to other browsers. The CGI or API scripts made the decision of which site to display based on whether the user-agent header contained the string "Mozilla/2" Microsoft, anxious that its users not be denied the wondrous user interface experience of frames, programmed Internet Explorer to pretend to be Netscape 2.0 so that publishers wouldn't have to rewrite their code.
ld20-147.compuserve.com - - [30/Jan/1997:18:28:50 -0500] "GET /samantha/samantha-III.html HTTP/1.0" 200 17298 http://www-swiss.ai.mit.edu/samantha/samantha-II.html "Mozilla/2.01E-CIS (Win16; I)"
 The host name tells us that this person is a CompuServe user. The
document requested was Chapter 3 and it was successfully delivered
(status code of 200; 17298 bytes served). The referer header is
"samantha-II.html", meaning that this reader was reading
Chapter II and then clicked on "next chapter." Finally, we
learn that the reader is running Netscape 2.01 on a Windows 3.1 box.
The host name tells us that this person is a CompuServe user. The
document requested was Chapter 3 and it was successfully delivered
(status code of 200; 17298 bytes served). The referer header is
"samantha-II.html", meaning that this reader was reading
Chapter II and then clicked on "next chapter." Finally, we
learn that the reader is running Netscape 2.01 on a Windows 3.1 box.
What are the subtleties here? First, the user might be coming through a caching proxy server. America Online, for example, doesn't let most of its users talk directly to your Web server. Why not? For starters, AOL Classic doesn't use Internet protocols so their users don't necessarily have software that understands TCP/IP or HTTP. Even if their users had Internet software, AOL has only a limited connection to the rest of the world. When 100 of their users request the same page, say, http://www.playboy.com, at around the same time, AOL would rather that only one copy of the page be dragged through their Internet pipe, so all of their users talk first to the proxy server. If the proxy has downloaded the page from the Internet recently, the cached copy is delivered to the AOL user. If there is no copy in the cache, the proxy server requests the page from Playboy's server and finally passes it on to the AOL customer.
A lot of companies require proxy connections for reasons of security. Ever since Java applets were introduced circa 1995 Web browsers have had the ability to run software downloaded from a publisher's site. This creates a security problem because a carefully crafted program might be able to, for example, read files on a user's computer and surreptitiously upload them to a foreign Web server. At most companies, the user's computer has the authority to read files from all over the internal company network. So one downloaded program on a Web page could potentially export all of a company's private data. On the other hand, if the company uses a firewall to force proxy connections, it can enforce a "no Java applet" policy. Computers with access to private information are never talking directly to foreign computers. Internal computers talk to the proxy server and the proxy server talks to foreign computers. If the foreign computer manages to attack the proxy server, that may interfere with Web browsing for employees but it won't compromise any internal data since the proxy server is outside of the company's private network.
Company security proxies distort Web server stats just as badly as AOL's private protocol-Internet bridge proxies. If you get more than 1000 requests every day from "minigun.ge.com" that doesn't necessarily mean one guy in the defense contracting division of General Electric loves your site; it could mean that "minigun" is the hostname of the computer that GE uses as its HTTP proxy server.
Despite the distortions you can rely on trends. If there are twice as many requests for a file today compared to six months earlier, readership is probably approximately double.
 If a Web site is very lightly used you can load the whole Web server
access log into a text editor and lovingly read it through line-by-line
tracing users' paths through site content. As a server becomes loaded,
however, and dozens of simultaneous users' requests are interwined this
kind of visual thread analysis becomes impossible.
If a Web site is very lightly used you can load the whole Web server
access log into a text editor and lovingly read it through line-by-line
tracing users' paths through site content. As a server becomes loaded,
however, and dozens of simultaneous users' requests are interwined this
kind of visual thread analysis becomes impossible.
 One approach to tracking an individual reader's surfing is to reprogram
your Web server to issue a magic cookie to every user of your
site. Every time a user requests a page, your server will check to see
if a cookie header has been sent by his browser. If not, your server
program will generate a unique ID and return the requested page with a
Set-Cookie header. The next time the user's browser requests a page from
your server, it will set the cookie header so that your server program
can log "user with browser ID #478132 requested
/samantha/samantha-III.html."
One approach to tracking an individual reader's surfing is to reprogram
your Web server to issue a magic cookie to every user of your
site. Every time a user requests a page, your server will check to see
if a cookie header has been sent by his browser. If not, your server
program will generate a unique ID and return the requested page with a
Set-Cookie header. The next time the user's browser requests a page from
your server, it will set the cookie header so that your server program
can log "user with browser ID #478132 requested
/samantha/samantha-III.html."
This gives you a very accurate count of the number of users on your Web site and it is easy to write a program to read the server log and print out actual user click streams.
Problems with this approach? Some users set their browsers to warn them before setting cookies. Some users or companies set their browsers to reject all cookies. If they reject the cookie that you try to set, their browser will never give it back to your server program. So you keep issuing cookies to users unable or unwilling to accept them. If such a user requests 50 documents from your server, casually implemented reporting software will see him as 50 distinct users requesting one document each.
 The number of click-throughs is information that is contained only in
Sally's server log. She can grind through her server log and look for
people who requested "/index.html" with a referer header of
"http://yoursite.com/page-with-banner-ad.html". Suppose your
arrangement with Sally is that she pays you 10 cents per
click-through. And further suppose that she has been hanging around with
Internet Entrepreneurs and has absorbed their philosophy. Here's how
your monthly conversation would go:
The number of click-throughs is information that is contained only in
Sally's server log. She can grind through her server log and look for
people who requested "/index.html" with a referer header of
"http://yoursite.com/page-with-banner-ad.html". Suppose your
arrangement with Sally is that she pays you 10 cents per
click-through. And further suppose that she has been hanging around with
Internet Entrepreneurs and has absorbed their philosophy. Here's how
your monthly conversation would go:
You: How many click-throughs last month, Sally?
Sally: Seven.
You: Are you sure? I had 28,000 hits on the page with the banner ad.
Sally: I'm sure. We're sending you a check for 70 cents.
You: Can I see your server logs?
Sally: Those are proprietary!
You: I think something may be wrong with your reporting software; I'd like to check.
Sally [sotto voce to her sysadmin]: "How long will it take to write a Perl script to strip out all but seven of the referrals from this loser's site? An hour? Okay."
Sally [to you]: "I'll put the log in a private directory on my server in about an hour."
Of course, Sally doesn't have to be evil-minded to deny you this information or deliver it in a corrupted form. Her ISP may be running an ancient Web server program that doesn't log referer headers. Some of your readers may be using browsers that don't supply referer headers. Sally may lack the competence to analyze her server log in any way.
What you need to do is stop linking directly to Sally. Link instead to a "click-through server" that will immediately redirect the user to Sally's site but keep a thread alive to log the click-through. If you have a low-tech site, your click-through script could dump an entry to a file. Alternatively, have the thread establish a connection to a relational database and record the click-through there.
Let's see if we can rob users of their privacy. In another era the author of this book operated an online photography community at photo.net and a separate server running the Bill Gates Personal Wealth Clock. The first step in the process was building a separate click-through server and adding an invisible GIF to the photo.net home page:
The URL is a coded reference to the click-through server. The first part of the URL, "blank", tells the click-through server to deliver a one-pixel blank GIF. The second part, "philg", says "this is for the philg realm, whose base URL is http://www.photo.net/". The last part is a URL stub that specifies where on the philg server this blank GIF is appearing.<img width=1 height=1 border=0 src="http://clickthrough.photo.net/blank/philg/photo/index.html">
This is a somewhat confusing way to use the Web that is possible with Web servers that allow a publisher to register a whole range of URLs, e.g., those starting with "blank", to be passed to a program. So this reference looks like it is grabbing a static .html page but actually it is running a script that ultimately returns a GIF.
If http://www.photo.net/photo/index.html is the first page that Joe User has ever requested with one of these GIFs from clickthrough.photo.net, his browser won't offer a cookie to clickthrough.photo.net. The script on the clickthrough server sees the cookie-less request and says, "Ah, new user, let's issue him a new browser_id and log this request with his IP address and user-agent header." If Joe is the sixth user that clickthrough.photo.net has ever seen, the script then issues a
This output header tells Joe's browser to return the string "ClickthroughNet=6" in a cookie header every time it requests any URL from clickthrough.photo.net (that's the "path=/" part). This cookie would normally expire when Joe terminated his browser session but it is possible to track Joe for a long period by explicitly setting the expiration date to January 1, 2010. (It is of course feasible to set the date even farther out but presumably by 2010 Joe will have abandoned all of his quaint notions about privacy and will be submitting his name, address, home phone number, social security number, and credit card numbers with every HTTP GET.)Set-Cookie: ClickthroughNet=6; path=/; expires=Fri, 01-Jan-2010 01:00:00 GMT
Every time Joe comes back to http://www.photo.net/photo/, his browser will
see the IMG reference to the click-through server again. Normally, his
browser would say, "Oh, that's a GIF that I cached two days ago so
I won't bother to rerequest it." However, the clickthrough server
script includes a "Pragma: no-cache" header
before the blank GIF. This instructs proxy servers and browser programs
not to cache the reference. They aren't required to obey this
instruction, but most do.
On his next visit to photo.net, Joe's browser will request the blank GIF again. This time, though, his browser will include a cookie header with his browser ID so the click-through server can just return the blank GIF and then keep a thread alive to log the access.
Now one can ask questions like "What are all the times that the user with browser_id 6 requested tagged pages from my server?" and "What percentage of users return to http://www.photo.net/photo/ more than twice a week?"
To make life a little more interesting, the next step was adding a little bit of code to the Bill Gates Personal Wealth Clock, which was then located at http://www.webho.com/WealthClock.
Note that www.webho.com is a different server from photo.net. If photo.net had issued Joe User's browser a cookie, his browser would not offer that cookie up to www.webho.com. But photo.net did not issue Joe a cookie; clickthrough.photo.net did. And that is the same server being referenced by the in-line IMG on the Wealth Clock. So the click-through server will be apprised of the access:<img width=1 height=1 border=0 src="http://clickthrough.photo.net/blank/webho/WealthClock">
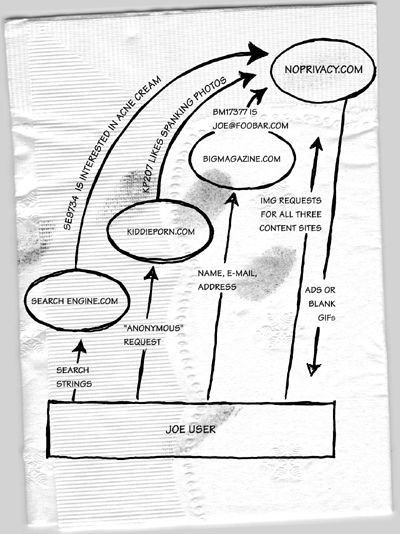
The final step is adding an extra few lines of code the my click-through stats collector. If there was a browser_id and detailed logging was enabled, then also write a log entry for the click-through.
After all of this evil work is done, what do we get?
We know that this guy was originally logged at 18.23.10.101 and that he is using Netscape 3.01 on Windows NT. We don't yet know his e-mail address, but only because he hasn't yet visited a guestbook page served by clickthrough.photo.net.Realm where originally logged: philg original IP address: 18.23.10.101 browser used initially: Mozilla/3.01 (WinNT; I) email address: CLICK STREAM 1997-01-30 01:44:36 Page View: philg/photo/index.html 1997-01-30 01:46:11 Page View: philg/photo/where-to-buy.html 1997-01-30 01:46:17 Clickthrough from text ref: philg/photo/where-to-buy.html to http://www.bhphotovideo.com/ 1997-01-30 02:30:46 Page View: webho/WealthClock 1997-01-31 13:13:17 Page View: webho/WealthClock 1997-02-01 08:04:15 Page View: philg/photo/index.html 1997-02-01 18:33:17 Page View: philg/photo/index.html 1997-02-03 12:46:18 Page View: philg/photo/where-to-buy.html 1997-02-03 14:53:56 Page View: webho/WealthClock
Then there is the click stream. We know that he downloaded the photo.net home page at 1:44 am on January 30, 1997. Two minutes later, he downloaded the "where to buy" page. Six seconds later, he clicked through to B&H Photo. Forty-five minutes later, he showed up on another server (the webho realm) viewing the Wealth Clock. The next day at 1:30 pm, this guy checks the Wealth Clock again. On February 1, 1997, he visits photo.net at 8:04 am and then again at 6:33 pm. He's back on the "where to buy" page on February 3. Two hours after that, he's checking the Wealth Clock once more . . .
If I get enough Web sites to cooperate in using one click-through server and even one of those sites requires registration, offers a contest, or does anything else where users type in names and e-mail addresses, it is only a matter of time before I can associate browser_id 6 with "joe4567@aol.com; Josephine Cunningham; 5 Oak St., Greenville, ME 04441."
Does all this sound too futuristic and sinister to be really happening?
Have a look at your browser's cookies file. With Internet Explorer, you
can find one file/cookie by doing Tools -> Internet Options ->
Settings -> View (Temporary) Files. See if there is are entries from
centralized ad serving companies such as ad.doubleclick.net.
 Suppose that the preceding talk about click-throughs and cookies has
overloaded your brain. You don't want to spend the rest of your life
programming SQL. You just want to analyze the server logs that you've
already got.
Suppose that the preceding talk about click-throughs and cookies has
overloaded your brain. You don't want to spend the rest of your life
programming SQL. You just want to analyze the server logs that you've
already got.
Is that worth doing?
Well, sure. As discussed in the first case above, you certainly want to find out which of your URLs are coughing up errors. If you have hundreds of thousands of hits per day, casual inspection of your logs isn't going to reveal the 404 File Not Found errors that make users miserable. This is especially true if your Web server program logs errors and successful requests into the same file.
You can also use the logs to refine content. You might find that half of your visitors were looking at the "About the Company" page rather than the "How to Buy the Product" section. Then it is time to examine the home page. Oops. The first link on the page is "About the Company". Perhaps that should be given less prominence.
You can also discover "hidden sites." You might have fallen prey to graphic designers and spent $20,000 designing http://yourdomain.com/entry-tunnel.html. But somehow the rest of the world has discovered http://yourdomain.com/old-text-site.html and is linking directly to that. You're getting 300 requests a day for the old page, whose information is badly organized and out of date. That makes it a hidden site. You'd ceased spending any time or money maintaining it because you thought there weren't any users. You probably want to either bring the site up to date or add a redirect to your server to bounce these guys to the new URL.
Finally, once your site gets sufficiently popular, you will probably turn off host name lookup. Attempting to look up every IP address (e.g., turning 18.30.0.217 into "lilac.lcs.mit.edu") is slow and sometimes causes odd server hangs. Anyway, after you turn lookup off, your log will be filled up with just plain IP addresses. You can use a separate machine to do the lookups offline and at least figure out whether your users are foreign, domestic, internal, or what.
 The first piece of Web "technology" that publishers acquire is
the Web server program. The second piece is often a log analyzer
program. Venture capitalists demonstrated their keen grasp of technology
futures by funding at least a dozen companies to write and sell
commercial log analyzer programs. This might have been a great strategy
if the information of importance to Web publishers were present in the
server log to begin with. Or if a bunch of more reliable freeware
programs wasn't available.
The first piece of Web "technology" that publishers acquire is
the Web server program. The second piece is often a log analyzer
program. Venture capitalists demonstrated their keen grasp of technology
futures by funding at least a dozen companies to write and sell
commercial log analyzer programs. This might have been a great strategy
if the information of importance to Web publishers were present in the
server log to begin with. Or if a bunch of more reliable freeware
programs wasn't available.
Anyway, be thankful that you didn't have money invested in any of these venture funds and that you have plenty of log analyzer programs from which to choose. These programs can be categorized along two dimensions:
Whether or not the source code is available is extremely important in a new field like Web publishing. As with Web server programs, software authors can't anticipate your needs or the evolution of Web standards. If you don't have the source code, you are probably going to be screwed in the long run. Generally the free public domain packages come with source code and the commercial packages don't.
A substrate-based log analyzer makes use of a well-known and proven system to do storage management and sometimes more. Examples of popular substrates for log analyzers are Perl and relational databases. A stand-alone log analyzer is one that tries to do everything by itself. Usually these programs are written in primitive programming languages like C and do storage management in an ad hoc manner. This leads to complex source code that you might not want to tangle with and, with some commercial products, crashes on logs of moderate size.
 If you just want some rough numbers, you don't need to bother with log
analyzers. Standard Unix shell commands, most of which are now
available on Windows machines as well, will tell you a lot.
If you just want some rough numbers, you don't need to bother with log
analyzers. Standard Unix shell commands, most of which are now
available on Windows machines as well, will tell you a lot.
If you've forgotten your Unix commands, pick up Unix Power Tools (Powers et al 2002; O'Reilly)
On the old photo.net Web site, AOLserver would roll the log file every
night at midnight. So the access log for Sunday, April 26th is called
"philg.log.98-04-27-00:00":
135 MB. Experience would suggest that this is probably about 700,000 hits. More precision is obtainable from the Unix word count facility:> ls -l -rw-r--r-- 1 nsadmin other 135288672 Apr 27 00:00 philg.log.98-04-27-00:00
Okay, it was 714,855 hits. What's the relative browser population?> wc -l philg.log.98-04-27-00:00 714855 philg.log.98-04-27-00:00
Looks like Netscape 2 and 4 were the leaders. Ooops, but let's recall that Microsoft pretends that MSIE is actually Netscape.> grep -c 'Mozilla/1' philg.log.98-04-27-00:00 4349 > grep -c 'Mozilla/2' philg.log.98-04-27-00:00 209128 > grep -c 'Mozilla/3' philg.log.98-04-27-00:00 130199 > grep -c 'Mozilla/4' philg.log.98-04-27-00:00 350763
Wow! 366,247 out of 714,855 hits were from Internet Explorer. Looks like the death of Netscape could have been foretold.> grep -c 'MSIE' philg.log.98-04-27-00:00 366247
What about content?
There are hardly any images underneath the /wtr/ pages ("Web Tools Review", a bunch of old articles on how to build Internet applications) so it looks as though there were 2,736 page loads. Remember that this log file is from a Sunday, when sane folks aren't working, so we'd expect traffic for nerd content like this to be lower than on weekdays.> grep -c 'GET /wtr/' philg.log.98-04-27-00:00 2736
What about programming mistakes, identified by the server delivering a page with a status code of 500?
The lens focal length calculator wasn't gracefully handling situations in which users left fields blank.> grep '" 500 ' philg.log.98-04-27-00:00 207.212.238.29 - - [26/Apr/1998:03:31:16 -0400] "POST /photo/tutorial/focal-length.tcl HTTP/1.0" 500 359 http://www.photo.net/photo/nikon/nikon-reviews.html "Mozilla/3.01 (Win95; I; 16bit)"
What about publishing mistakes, identified by the server delivering pages with a status code of 404 ("Not Found")?
Shell tools can almost always answer your questions but they're a very cumbersome way of discovering patterns for which you weren't looking.> grep '" 404 ' philg.log.98-04-27-00:00 204.94.209.1 - - [26/Apr/1998:02:56:55 -0400] "GET /photo/nikon/comparison-chart HTTP/1.0" 404 537 http://www.zaiko.kyushu-u.ac.jp/~walter/nikon.html#slr "Mozilla/4.04C-SGI [en] (X11; I; IRIX 6.2 IP22)" 207.170.89.121 - - [26/Apr/1998:22:20:28 -0400] "GET /photo/what-camera-should-I-bu HTTP/1.0" 404 537 http://www.productweb.com/c/index.cfm?U1=216406052&CategoryID=948&CategoryName=Cameras%2C%2035mm&guidesOn=1&PageName=948.4.1 "Mozilla/4.04 [en] (Win95; I)"
 There are a bunch of purpose-built log analyzers listed in
http://www.yahoo.com/Computers_and_Internet/Software/Internet/World_Wide_Web/Servers/Log_Analysis_Tools/,
one of the most popular of which is the free and open-source Analog.
There are a bunch of purpose-built log analyzers listed in
http://www.yahoo.com/Computers_and_Internet/Software/Internet/World_Wide_Web/Servers/Log_Analysis_Tools/,
one of the most popular of which is the free and open-source Analog.
The basic idea with these tools is that they aggregate statistics from one or more days of servers logs and present intelligible, often graphical, summaries of those statistics. For high-volume sites the tools may keep a file of cumulative stats from older log files and add to those stats every night as a new log file is processed. This can be scary if the tool is closed-source and its format is undocumented and the vendor is a company other than Microsoft.
Maybe it would be wise to give cumulative data a more stable footing...
 What are the characteristics of our problem anyway? Here are some
obvious ones:
What are the characteristics of our problem anyway? Here are some
obvious ones:
This could be the best of all possible worlds. You do not surrender control of your data. With a database-backed system, the data model is exposed. If you want to do a custom query or the monolithic program crashes, you don't have to wait four months for the new version. Just go into a standard database client and type your query. If the vendor decides that that they've got better things to do than write log analyzers, at least Oracle and Microsoft SQL Server will be around. Furthermore, SQL is standard enough that you can always dump your data out of Brand O into Brand M or vice versa.
More importantly, if you decide to get a little more ambitious and start logging click-throughs or sessions, you can use the same RDBMS installation and do SQL JOINs on the vanilla server log tables and the tables from your more sophisticated logs.
Caveats? Maintaining a relational database is not such a thrill, though using it for batch inserts isn't too stressful. If you don't want the responsibility of keeping the RDBMS up 7x24 then you can have your Web server log to a file as usual and insert the data into your RDBMS in batches.
If you do decide to go for real-time logging, be a little bit thoughtful about how many inserts per second your RDBMS can handle. You should start to worry if you need to log more than 10 hits per second on a standard pizza box server with one disk drive.
We've discussed how to track the user. Now let's think about how to use the data collected to help the user.
 My favorite course to teach at MIT is 6.041, a probability class
designed by Al Drake, one of the fully-human human beings who never
seem to get past tenure committees these days. Drake taught the course
for decades and wrote the text,
Fundamentals
of Applied Probability Theory, which offers the
clearest explanation of statistics that I've seen.
My favorite course to teach at MIT is 6.041, a probability class
designed by Al Drake, one of the fully-human human beings who never
seem to get past tenure committees these days. Drake taught the course
for decades and wrote the text,
Fundamentals
of Applied Probability Theory, which offers the
clearest explanation of statistics that I've seen.
Each week in 6.041, we meet with students in small groups. Victims go up to the blackboard and work through problems that they haven't seen before. Partly the idea is to see how they think and offer corrections. Partly the idea is to prepare them to give engineering presentations and communicate their ideas. The student at the board isn't really supposed to solve the problem, just coordinate hints from other students at the conference table.
One day it was Anne's turn. This quiet midwestern girl studied the problem for a moment, walked over to the board, and gave a five minute presentation on how to solve it, mentioning all of the interesting pedagogical points of the problem and writing down every step of the solution in neat handwriting. Her impromptu talk was better prepared than any lecture I'd ever given in the class.
Afterwards we had a little chat.
"What did you do on Sunday?" she asked.
"Oh, let's see... Ate. Brushed the dog. Watched The Simpsons. And you?" I replied.
"My housemates and I decided to have a hacking party. We do this every month or so. Since we have a network of PCs at home, it is easy to get lots of people programming together. We couldn't decide what to build so I said ‘Well, we all like science fiction novels. So let's build a system where we type in the names of the books that we like and a rating. Then the system can grind over the database and figure out what books to suggest.'"
And?
"It took us the whole afternoon, but we got it to the point where it would notice that I liked Books A, B, and C but hadn't read Book D, which other people who liked A, B, and C had liked. So that was suggested for me. We also got it to notice if you and I had opposite tastes and suppress your recommendations."
This was back in 1994. Anne and her friends had, in one afternoon, completed virtually the entire annual research agenda of numerous American university professors and the development agenda of quite a few venture capital-backed companies.
The first lesson to be drawn from this example is that Anne is a genius [n.b. she went to work at Microsoft after graduating from MIT]. The second is that an afternoon hack, even by a genius, isn't enough to solve the personalization problem. Yet if you cut through the crust of hype that surrounds any of the expensive Web server personalization software "solutions", all that you find underneath is Anne's afternoon hack.
What's wrong with Anne's system? First, it imposes a heavy burden of logging in and rating on users. Given that we're going to lose our privacy and have an unfeeling computer system know everything about our innermost thoughts and tastes, can't it at least be a painless process?
Suppose we did get everyone in the world to subscribe to Anne's system and tirelessly rate every Usenet posting, every Web site, every musical composition, every movie, every book. Does this help Joe User make the choices that matter? If Joe types in that he likes the Waldstein sonata, probably Anne's software can tell him that he wouldn't like the Pat Boone cover of AC/DC's It's a Long Way to the Top (If You Wanna Rock and Roll). But will it help him pick among Beethoven's other 31 piano sonatas? Is it meaningful to rate Beethoven's sonatas on a linear scale: Pastoral good, Appassionata great, Moonlight, somewhere in between?
Suppose Joe User's taste changes over time? Consider that old French saying: "If you're not a liberal when you're young, then you have no heart; if you're not a conservative when you're old, then you have no mind." Perhaps he liked Guy de Maupassant and Charles Dickens when he was foolish and young but now that he's old, he's come to see the supreme truth of Ayn Rand. Joe doesn't want Anne's system recommending a bunch of books about sissies helping each other when he could be reading about a perfect society where rich people rent rather than loan their cars to friends.
That's no big deal. We'll just expire the ratings after 10 years. But what if Joe's taste changes over the course of a few days? Last week Joe was content to sit through four hours of Hamlet. This week Joe has had to go back to his Dodge dealer four times to get the rattling plastic pieces on the interior stuck back to the metal; he needs a comedy.
The late Ken Phillips, a professor at New York University, figured this out in the late 1970s when he set up a massive computer network for Citibank. He would ask folks what they thought AT&T's most valuable asset was. People would try to estimate the cost of undersea cables versus the fiber links that crisscross the continent. Ken laughed.
"AT&T gives you long distance service so they know which companies you call and how long you spend on the phone with each one. AT&T gives you a credit card so they know what you buy. AT&T owns Cellular One so, if you have a cell phone, they know where you drive and where you walk. By combining these data, AT&T can go to a travel agency and say ‘For $100 each, we can give you the names of people who drive by your office every day, who've called airline 800 numbers more than three times in the last month, who have not called any other travel agencies, and who have spent more than $10,000 on travel in the last year.'"
Ken was ahead of his time.
As discussed above, Web publishers and marketeers are trying to do some of this with persistent magic cookies issued by central ad delivery/tracking services. However, these systems are extremely crude compared to traditional direct marketing databases.
Compare the relevancy of the junk snail mail that you receive to that of the spam email cluttering your inbox. Your behavior on the Web is much more consistently logged than your behavior in real life. Why then is your Internet profile so much less accurate? Partly because Web data are fragmented. Information about which files you've downloaded is scattered among many different sites' server logs. But mostly because publishers don't know what to do with their data. Server-side junkware and Web site marketeers are invariably expert at telling a story about all the wonderful data that they can collect. Occasionally they actually do collect and store these data. However, once data goes into the big user tracking table, they seldom come back out.
Before considering smarter server-side approaches, let's ask ourselves if the server is the right place to be doing personalization.
 Suppose that the U.S. government decides to stop suing Microsoft and
start using Linux (see
http://philip.greenspun.com/humor/bill-gates).
Then consider the case of Jane Civil Servant who telecommutes from her
home office and is currently taking a break to browse the Web from her
desktop Linux box. If publishers added semantic tags to their sites
(see Chapter 5), her Web browser could warn her
that the software whose blurbs she was investigating weren't available
for Linux. Her desktop machine knows not only which Web pages she has
downloaded, but also how long she has spent viewing each one. It knows
which Web pages she has deemed important enough to save to her local
disk. Her desktop machine knows that she's sent a bunch of e-mail today
to friends asking for tips on places to visit in California. It can
listen to her phone line and figure out that she has called 10 numbers
in California today. You'd think that her desktop machine could put all
of this together to say, "Jane, you should probably check out http://www.photo.net/ca/. I also note that you've been
typing at the keyboard on this machine for an average of 11 hours every
day for the last two weeks. You ought to relax tonight. I notice from
your calendar program that you don't have any appointments. I notice
from your Quicken database that you don't have any money so you probably
shouldn't be going to the theater. I notice that Naked
Gun is on cable tonight. I don't see any payments in your
Quicken database to a cable TV vendor so I assume you aren't a Cable
Achiever. I remember seeing some e-mail from your friend David two
months ago containing the words "invite" and "cable
TV" so I assume that David has cable. I see from watching your
phone line's incoming caller line ID that he has called you twice in the
last week from his home phone so I assume he is in town. Call him up and
invite yourself over."
Suppose that the U.S. government decides to stop suing Microsoft and
start using Linux (see
http://philip.greenspun.com/humor/bill-gates).
Then consider the case of Jane Civil Servant who telecommutes from her
home office and is currently taking a break to browse the Web from her
desktop Linux box. If publishers added semantic tags to their sites
(see Chapter 5), her Web browser could warn her
that the software whose blurbs she was investigating weren't available
for Linux. Her desktop machine knows not only which Web pages she has
downloaded, but also how long she has spent viewing each one. It knows
which Web pages she has deemed important enough to save to her local
disk. Her desktop machine knows that she's sent a bunch of e-mail today
to friends asking for tips on places to visit in California. It can
listen to her phone line and figure out that she has called 10 numbers
in California today. You'd think that her desktop machine could put all
of this together to say, "Jane, you should probably check out http://www.photo.net/ca/. I also note that you've been
typing at the keyboard on this machine for an average of 11 hours every
day for the last two weeks. You ought to relax tonight. I notice from
your calendar program that you don't have any appointments. I notice
from your Quicken database that you don't have any money so you probably
shouldn't be going to the theater. I notice that Naked
Gun is on cable tonight. I don't see any payments in your
Quicken database to a cable TV vendor so I assume you aren't a Cable
Achiever. I remember seeing some e-mail from your friend David two
months ago containing the words "invite" and "cable
TV" so I assume that David has cable. I see from watching your
phone line's incoming caller line ID that he has called you twice in the
last week from his home phone so I assume he is in town. Call him up and
invite yourself over."

We trust our desktop computers with our e-mail. We trust them with our credit card numbers. We trust them to monitor our phone calls. We trust our desktop computers with financial and tax data. We can program our desktop computers to release or withhold information without relying on publishers' privacy notices. If publishers would stop trying to be clever behind our backs, most of us would be happy to give them personal information of our choosing.
The foregoing is not meant as an argument against mobile computing, by the way. Nor is it meant to vitiate the argument presented in Chapter 1 that progress in computing won't occur until we move away from desktop-centric applications. People who are heavily dependent on mobile computing can simply designate a single hard-wired computer as their personalization proxy, more or less like the Internet Fish that Brian LaMacchia built back in 1995 (see www.farcaster.com; yet another MIT genius who ended up at Microsoft). These are "semi-autonomous, persistent information brokers; users deploy individual IFish to gather and refine information related to a particular topic. An IFish will initiate research, continue to discover new sources of information, and keep tabs on new developments in that topic. As part of the information-gathering process the user interacts with his IFish to find out what it has learned, answer questions it has posed, and make suggestions for guidance." As far as a Web publisher is concerned, a proxy such as an Internet Fish looks exactly the same as a desktop client.
Publishers can help client-side systems by adding semantic tags to their content, as discussed in Chapter 5 where it is also noted with dismay that publishers can't currently do the right thing. There is no agreed-upon language for tagging the semantics of Web documents. Against the day that the XML folks make real progress, Publisher can be ready for that day by keeping content in a more structured, more semantically meaningful form than HTML, i.e., a database.
What would www.adobe.com look like if we added quiet server-side personalization? As of August 1998, the home page offers a choice of paths into the content. A reader can choose by language, by product, or by verb (e.g., download or discuss). Consider the case of Yoshito Morita who, from the same browser, does the following:
There should be two links following this question. The "I'd like to buy an upgrade now" link would take Yoshito to an order form. The "I already upgraded" link would take Yoshito to a form to register his new purchase (and do the market research of asking where he bought it).

Google Analytics implements a "magic cookie" approach similar to that described by this chapter, except it relies on Javascript. It's quite helpful, although it still isn't anywhere near as powerful as something you rolled on your own.
-- John Lee, December 17, 2006