You're also going to learn about the stateless and anonymous protocol that makes Web development different from classical inter-computer application development. You'll learn why the relational database management system is key to controlling the concurrency problem that arises from multiple simultaneous users. You'll develop software to read and write Extensible Markup Language (XML).
**** insert figure here ****
Figure 2.1: In a traditional stateful communications protocol, two programs running on two separate computers establish a connection and proceed to use that connection for as long as necessary, typically until one of the programs terminates.
The most important thing to know about HTTP is that it is stateless. If you view ten Web pages, your browser makes ten independent HTTP requests of the publisher's Web server. At any time in between those requests, you are free to restart your browser program. At any time in between those requests, the publisher is free to restart its server program.
Here's the anatomy of a typical HTTP session:
In this case we've used the Unix
telnet command with an
optional argument specifying the port number for the target
host--everything typed by the programmer is here indicated in bold.
We typed the "GET ..." line ourselves and then hit Enter twice on the
keyboard. Yahoo's first header back is "HTTP/1.0 200 OK". The HTTP
status code of 200 means that the file was found ("OK").
See the HTTP standard at http://www.w3.org/Protocols/ for more information on HTTP.
Don't get too lost in the details of the HTTP example. The point is that when the connection is over, it is over. If the user follows a hyperlink from the Yahoo front page to "Photography," for example, that's a brand new HTTP request. If Yahoo is using multiple servers to operate its site, the second request might go to an entirely different machine. This sounds fine for browsing Yahoo. But suppose you're shopping at an e-commerce site such as Amazon. If you put something in your shopping cart on one HTTP request, you still want it to be there ten clicks later. Or suppose you've logged into photo.net on Click 23 and on Click 45 are responding to a discussion forum posting. You don't want the photo.net server to have forgotten your identity and demand your username and password again.
This presents you, the engineer, with a challenge: creating a stateful user experience on top of a fundamentally stateless protocol.
Where can you store state from request to request? Perhaps in a log file on the Web server. The server would write down "Joe Smith wants three copies of Bus Nine to Paradise by Leo Buscaglia". On any subsequent request by Joe Smith, the server-side script can simply check the log and display the contents of the shopping cart. A problem with this idea, however, is that HTTP is anonymous. A Web server doesn't know that it is Joe Smith connecting. The server only knows the IP address of the computer making the request. Sometimes this translates into a host name. If it is joe-smiths-desktop.stanford.edu, perhaps you can identify subsequent requests from this IP address as coming from the same person. But what if it is cache-rr02.proxy.aol.com, one of the HTTP proxy servers connecting America Online's 20 million users to the public Internet? The same user's next request will very likely come from a different IP address, i.e., another physical computer within AOL's racks and racks of proxy machines. The next request from cache-rr02.proxy.aol.com will very likely come from a different person, i.e., another physical human being among AOL's 20 million subscribers who share a common pool of proxy machines.
Somehow you need to write some information out to an individual user that will be returned on that user's next request.
If all of your pages are generated by computer programs as opposed to being static HTML, one idea would be to rewrite all the hyperlinks on the pages served. Instead of sending the same files to everyone, with the same embedded URLs, customize the output so that a user who follows a link is sending extra information back to the server. Here is an example of how amazon.com embeds a session key in URLs:
The HTTP protocol does not place any a priori limit on the length of a URI. Servers MUST be able to handle the URI of any resource they serve, and SHOULD be able to handle URIs of unbounded length if they provide GET-based forms that could generate such URIs. A server SHOULD return 414 (Request-URI Too Long) status if a URI is longer than the server can handle (see section 10.4.15).There is no need to worry about turning away Amazon's best customers, the ones with really big shopping carts, with a return status of "414 Request-URI Too Long". Or is there? Here is a comment from the HTTP spec:
Note: Servers ought to be cautious about depending on URI lengths above 255 bytes, because some older client or proxy implementations might not properly support these lengths.Perhaps this is why the real live amazon.com stores only session ID in the URLs.
Cookies are a general mechanism which server side connections (such as CGI scripts) can use to both store and retrieve information on the client side of the connection. The addition of a simple, persistent, client-side state significantly extends the capabilities of Web-based client/server applications.How does it work? After Joe Smith adds a book to his shopping cart, the server writes
Set-Cookie: cart_contents=1588750019; path=/
As long as Joe does not quit his browser, on every subsequent request
to your server, the browser adds a header:
Cookie: cart_contents=1588750019
Your server-side scripts can read this header and extract the current
contents of the shopping cart.
Sound like the perfect solution? In some ways it is. If you're a computer science egghead you can take pride in the fact that this is a distributed database management system. Instead of keeping a big log file on your server, you're keeping bits of information on thousands of users' machines worldwide. But one problem with cookies is that the spec limits you to asking each browser to store no more than 20 cookies on behalf of your server and each of those cookies must be no more than 4 kilobytes in size. A minor problem is that cookie information will be passed back up to your server on every page load. If you have indeed indulged yourself by parking 80 Kbytes of information in 20 cookies and your user is on a modem, this is going to slow down Web interaction.
A deeper problem with cookies is that they aren't portable for the user. If Joe Smith starts shopping from his desktop computer at work and wants to continue from a mobile phone in a taxi or from a Web browser at home, he can't retrieve the contents of his cart so far. The shopping cart resides in the memory of his computer at work.
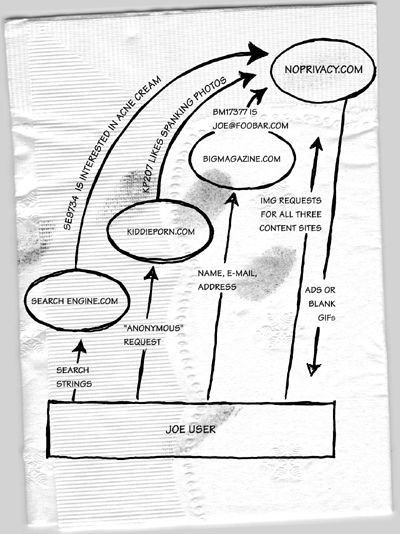
A final problem with cookies is that a small percentage of users have disabled them due to the privacy problems illustrated in figure 2.2.
Figure 2.2: Cookies coupled with the open-hearted behavior of 1990s browsers meant the end of privacy on the Internet. Suppose that three publishers cooperate and agree to serve all of their banner ads from http://noprivacy.com. When Joe User visits search-engine.com and types in "acne cream", the page comes back with an IMG referencing noprivacy.com. Joe's browser will automatically visit noprivacy.com and ask for "the GIF for SE9734". If this is Joe's first time using any of these three cooperating services, noprivacy.com will issue a Set-Cookie header to Joe's browser. Meanwhile, search-engine.com sends a message to noprivacy.com saying "SE9734 was a request for acne cream pages." The "acne cream" string gets stored in noprivacy.com's database along with "browser_id 7586." When Joe visits bigmagazine.com, he is forced to register and give his name, e-mail address, Snail mail address, and credit card number. There are no ads in bigmagazine.com. They have too much integrity for that. So they include in their pages an IMG referencing a blank GIF at noprivacy.com. Joe's browser requests "the blank GIF for BM17377" and, because it is talking to noprivacy.com, the site that issued the Set-Cookie header, the browser includes a cookie header saying "I'm browser_id 7586." When all is said and done, the noprivacy.com folks know Joe User's name, his interests, and the fact that he has downloaded six spanking JPEGs from kiddieporn.com.
A reasonable engineering approach to using cookies is to send a unique identifier for the data rather than the data, just as in the amazon.com "session ID in the URL" example previously described. Information about the contents of the shopping cart will be kept in some sort of log on the server. This means that it can be picked up from another location. To see how this works in practice, go to an operating system shell and request the home page of photo.net:
Note that two cookies are set. The first one,
ad_browser_id is given an explicit expiration date in
January 2010. This instructs the browser to record the cookie value,
in this case "3291092," on the hard drive. The cookie's value will
continue to be sent back up to the server for the next five years,
even if the user quits and restarts the browser. What's the point of
having a browser cookie? If the user says "I prefer text-only" or "I
prefer French language" that's probably worthwhile information to keep
with the browser. The text-only preference may be related to a slow
Internet connection to that computer. If the computer is in a home
full of Francophones, chances are that all the people who share the
browser will prefer French.
The second cookie set, ad_session_id is set to expire
after one hour ("Max-Age=3600"). If not explicitly set to expire, it
would expire when the user quit his or her browser. Things worth
associating with a session ID include the contents of a shopping cart
on an e-commerce site, though note that if photo.net were a shopping
site, it would not be a good idea to expire the session cookie after
one hour! It is annoying to build up a cart, be called away from your
computer for a few hours, and then have to start over when you return
to what you thought was a working Web page.
If we were logged into photo.net, there would be a third cookie, one that identifies the user. Languages and presentation preferences stored on the server on behalf of the user would then override preferences kept with the browser ID.
For flexibility in how you present and analyze user-contributed data, you'll probably want to keep the information in a structured form. For example, it would be nice to have a table of all the items put into shopping carts by various users. And another table of orders. And another table of reader-contributed product reviews. And another table of questions and answers.
What's a good tool for storing tables of information? Consider first a spreadsheet program. These are inexpensive and easy to use. One should never apply more complex technology than necessary for solving a problem. Something like Visicalc, Lotus 1-2-3, Microsoft Excel, or StarOffice Calc would seem to serve nicely.
The problem with a spreadsheet program is that it is designed for one user. The program listens for user input from two sources: mouse and keyboard. The program reports its results to one place: the screen. Any source of persistence for a Web server has to contend with potentially thousands of simultaneous users both reading and writing to the database. This is the problem that database management systems (DBMS) were intended to solve.
A good way to think about a relational database management system (RDBMS, the most popular type of DBMS) is as a spreadsheet program that sits inside a dark closet. If you need to create a new table you slip a little strip of paper under the door with "CREATE TABLE ..." written on it. To add a row of data to that table, you slip another little strip under the door saying "INSERT...". To change some data within the table, you write "UPDATE.. " on a paper strip. To remove a row, you send in a strip starting with "DELETE".
Notice that we've solved the concurrency problem here. Suppose that you have only one copy of Bus Nine to Paradise left in inventory and 1000 users at the same instant request Dr. Buscaglia's work. By arranging the strips of paper in a row, the program in the closet can decide to process one INSERT into the orders table and reject the 999 others. This is better than 1000 people fighting over a single keyboard and mouse.
Once we've sent information into the closet, how do we get it back out? We can write down a request for a report on a strip of paper starting with "SELECT" and slide it under the door. The DBMS in the dark closet will prepare a report for us and slide that back to us under the same door.
How do we evaluate whether or not a DBMS is powerful enough for our application? Starting in the 1960s IBM proposed the "ACID test":
- Atomicity
- Results of a transaction's execution are either all committed or all rolled back. All changes take effect, or none do. Suppose that a user is registering by uploading name, address, and JPEG portrait into three separate tables. A Web script tells the database to perform three inserts as part of a transaction. If the hard drive fills up after the name and address have been inserted but before the portrait can be stored, the changes to the name and address tables will be rolled back.
- Consistency
- The database is transformed from one valid state to another valid state. A transaction is legal only if it obeys user-defined integrity constraints. Illegal transactions aren't allowed and, if an integrity constraint can't be satisfied, the transaction is rolled back. For example, suppose that you define a rule that postings in a discussion forum table must be attributed to a valid user ID. Then you hire Joe Novice to write some admin pages. Joe writes a delete-user page that doesn't bother to check whether or not the deletion will result in an orphaned discussion forum posting. An ACID-compliant DBMS will check, though, and abort any transaction that would result in you having a discussion forum posting by a deleted user.
- Isolation
- The results of a transaction are invisible to other transactions until the transaction is complete. For example, suppose you have a page to show new users and their photographs. This page is coded in reliance on the publisher's directive that there will be a portrait for every user and will present a broken image if there is not. Jane Newuser is registering at your site at the same time that Bill Olduser is viewing the new user page. The script processing Jane's registration has completed inserting her name and address into their respective tables. But it is not done storing her JPEG portrait. If Bill's query starts before Jane's transaction commits, Bill won't see Jane at all on his new-users page, even though Jane's insertion into some of the tables is complete.
- Durability
- Once committed (completed), the results of a transaction are permanent and survive future system and media failures. Suppose your e-commerce system inserts an order from a customer into a database table and then instructs CyberSource to bill the customer $500. A millisecond later, before your server has heard back from CyberSource, someone trips over the machine's power cord. An ACID-compliant DBMS will not have forgotten about the new order. Furthermore, if a programmer spills coffee into a disk drive, it will be possible to install a new disk and recover the transactions up to the coffee spill, showing that you tried to bill someone for $500 and still aren't sure what happened over at CyberSource. Notice that to achieve the D part of ACID requires that your computer have more than one hard disk.
The first pillar of RDBMS popularity is a declarative query language called "SQL". The most common style of programming is not declarative; it is called "imperative" or "procedural". You tell the computer what to do, step by step:
An alternative style of programming is "declarative". We tell the computer what we want, e.g., a report of users who've been registered for more than one year but who haven't answered any questions in the discussion forum. We don't tell the RDBMS whether to scan the users table first and then check the discussion forum table or vice versa. We just specify the desired characteristics of the report and it is the job of the RDBMS to prepare it.
Stop someone in the street. Pick someone with fashionable clothing so you can be sure he or she is not a professional programmer. Ask this person, "Have you ever programmed in a declarative computer language?" Follow that up with "Have you ever used a spreadsheet program?" Chances are that you can find quite a few people who will tell you that they've never written any kind of computer program but yet they've developed fairly sophisticated spreadsheet models. Why? The spreadsheet language is declarative: "Make this cell be the sum of these three other cells". The user doesn't tell the spreadsheet program in what order to perform the computation, merely the desired result.
The declarative language of the spreadsheet created an explosion in the number of people who were able to develop working computer programs. Through the mid-1970s, organizations that worked with data kept a staff of programmers. If you wanted some analysis performed you'd call one into your office, explain the assumptions and formulae to be used, then wait a few days for a report. In 1979 Dan Bricklin (MIT EECS '73) and Bob Frankston (MIT EECS '70) developed Visicalc and suddenly most of the people who'd been hollering for programming services were able to build their own models.
With an RDBMS the metaphoric little strips of paper pushed under the door are declarative programs in the SQL language. (See SQL for Web Nerds at http://philip.greenspun.com/sql/ for a SQL language tutorial.)
The second pillar of RDBMS popularity is isolation of important data from programmers' mistakes. With other kinds of database management systems it is possible for a computer program to make arbitrary changes to the data set. This can be convenient for applications such as computer-aided design systems with very complex data structures. However if your goal is to preserve a data set over a twenty-five-year period, letting arbitrarily buggy imperative programs make arbitrary changes isn't a good idea. The RDBMS limits programmers to uttering very simple statements of the form INSERT, DELETE, and UPDATE. Furthermore, if you're unhappy with the contents of your database you can simply review all the strips of paper that were pushed under the door. Each strip will contain an SQL statement and the name of the program or programmer that authored the strip. This makes it easy to correct mistakes and reform offenders.
The third and final pillar of RDBMS popularity is good performance with many thousands of simultaneous users. This is more a reflection on the refined state of commercial development of systems such as IBM DB2, Oracle, Microsoft SQL Server, and the open-source PostgreSQL, than an inherent feature of the RDBMS itself.
Step 4 is intellectually uninteresting and also uninteresting from an engineering point of view. An Internet service lives or dies by Steps 1 through 3. What can the service do for the user? Is the page flow comprehensible and usable? The answers to these questions are determined at Steps 1 through 3. However, Step 4 is where you have a huge range of technology choices and therefore it seems to generate a lot of discussion. This course and this book are neutral on the subject of how you go about Step 4 but we provide some guidance on how to make choices.
First, though, let's step back and make sure that everyone knows HTML.
My Samoyed is really hairy.
That is a perfectly acceptable HTML document. Type it up in a text editor, save it as index.html, and put it on your Web server. A Web server can serve it. A user with Netscape Navigator can view it. A search engine can index it.
Suppose you want something more expressive. You want the word really to be in italic type:
My Samoyed is <I>really</I> hairy.
HTML stands for Hypertext Markup Language. The <I> is markup. It tells the browser to start rendering words in italics. The </I> closes the <I> element and stops the italics. If you want to be more tasteful, you can tell the browser to emphasize the word really:
My Samoyed is <EM>really</EM> hairy.
Most browsers use italics to emphasize, but some use boldface and browsers for ancient ASCII terminals (e.g., Lynx) have to ignore this tag or come up with a clever rendering method. A picky user with the right browser program can even customize the rendering of particular tags.
There are a few dozen more tags in HTML. You can learn them by choosing View Source from your Web browser when visiting sites whose formatting you admire. You can look at the HTML reference chapter of this book. You can learn them by starting at Yahoo's directory of HTML guides and tutorials, http://dir.yahoo.com/Computers_and_Internet/Data_Formats/HTML/Guides_and_Tutorials/. Or you can buy HTML & XHTML: The Definitive Guide (Musciano and Kennedy; O'Reilly, 2002).
Another structure issue is that you should try to make sure that you close every element that you open. If your document has a <BODY> it should have a </BODY> at the end. If you start an HTML table with a <TABLE> and don't have a </TABLE>, a browser may display nothing. Tags can overlap, but you should close the most recently opened before the rest, e.g., for something both boldface and italic:
My Samoyed is <B><I>really</I></B> hairy.
Something that confuses a lot of new users is that the <P> element used to surround a paragraph has an optional closing tag </P>. Browsers by convention assume that an open <P> element is implicitly closed by the next <P> element. This leads a lot of publishers (including lazy old us) to use <P> elements as paragraph separators.
Here's the source HTML from a simply formatted Web document:
<html> <head> <title>Nikon D1 Digital Camera Review</title> </head> <body bgcolor=white text=black> <h2>Nikon D1</h2> by <a href="http://philip.greenspun.com/">Philip Greenspun</a> <hr> Little black spots are appearing at the top of every ... <h3>Basics</h3> The Nikon D1 is a good digital camera for ... <p> The camera's 15.6x23.7mm CCD image sensor ... <h3>User Interface</h3> If you wanted a camera with lots of buttons, switches, and dials ... <hr> <address> <a href="mailto:philg@mit.edu">philg@mit.edu</a> </address> </body> </html>
Let's go through this document piece by piece (see  for how it looks rendered by a browser).
for how it looks rendered by a browser).
The <HTML> tag at the top says "I'm an HTML document". Note that this tag is closed at the end of the document. It turns out that this tag is unnecessary. We've saved the document in the file "simply-page.html". When a user requests this document, the Web server looks at the ".html" extension and adds a MIME header to tell the user's browser that this document is of type "text/html".
The HEAD element here is useful mostly so that the TITLE element can be used to give this document a name. Whatever text you place between <TITLE> and </TITLE> will appear at the top of the user's browser window, on the Go (Netscape) or Back (MSIE) menu, and in the bookmarks menu should the user bookmark this page. After closing the head with a </HEAD>, we open the body of the document with a <BODY> tag, to which are added some parameters that set the background to white and the text to black. Some Web browsers default to a gray background, and the resulting lack of contrast between background and text is so tough on users that it may be worth changing the colors manually. This is a violation of interface design principles since it potentially introduces an inconsistency in the user's experience of the Web. However, we do it at photo.net without feeling too guilty about it because (1) a lot of browsers use a white background by default, (2) enough other publishers set a white background that our pages won't seem inconsistent, and (3) it doesn't affect the core user interface the way that setting custom link colors would.
Just below the body, we have a headline, size 2, wrapped in an
<H2> tag. This will be displayed to the user at the top of
the page. We probably should use <H1> but browsers typically
render that in a frighteningly huge font. Underneath the headline, the
phrase "Philip Greenspun" is a hypertext anchor which is why it
is wrapped in an A element. The <A HREF= says "this is a
hyperlink." If the reader clicks anywhere from here up to the
</A> the browser should fetch http://philip.greenspun.com/.
After the headline, author, and optional navigation, we put in a horizontal rule tag: <HR>. One of the good things that we learned from designer Dave Siegel (see http://philip.greenspun.com/wtr/getting-dates) is not to overuse horizontal rules: Real graphic designers use whitespace for separation. We use <H3> headlines in the text to separate sections and only put an <HR> at the very bottom of the document.
Underneath the last <HR>, we sign our documents with the email address of the author. This way a reader can scroll to the bottom of a browser window and find out who is responsible for what they've just read and where to send corrections. The <ADDRESS> tag usually results in an italics rendering by browser programs. Note that this one is wrapped in an anchor tag with a target of "mailto:" rather than "http:". If the user clicks on the anchor text (Philip's email address), the browser will pop up a "send mail to philg@mit.edu" window.
For experienced Windows programmers, Microsoft SQL Server is easy to install and administer. And if you expect to spend the rest of your professional life in a Microsoft environment you might as well learn it.
Concurrency is Oracle's strongest suit relative to its commercial
competitors. In Oracle, readers never wait for writers and writers
never wait for readers. Suppose the publisher at a large site starts
a query at 12:00 PM summarizing usage by user. Oracle might have to
spend an hour sifting through 200 GB of tracking data. The disk
drives grind and one CPU is completely used up until 1:30 PM. Further
suppose that User #356712 comes in at 12:30 PM and changes his email
address, thus updating a row in the users table. If the
usage tracking query arrives at this row at 12:45 PM, Oracle will
notice that the row was last modified after the query started. Under
the "I" in ACID, Oracle is required to isolate the publisher from the
user's update. Oracle does this by reaching into the rollback segment
and producing data from user row #356712 as it was at 12:00 PM when
the query started. Here's the scenario in a table:
How would this play out in Microsoft SQL Server? When you're reading, you take read locks on the information that you're about to read. Nobody can write until you release them. When you're writing, you take write locks on the information that you're about to update. Nobody can read or write until you release the locks. In the preceding example, User #356712 would submit his request for the address change at 12:30 PM. The thread on the Web server would be blocked waiting for the read locks to clear. How long would it wait? A full hour with a spinning/waving "browser still receiving information" icon in the upper right corner of the browser window. If you're thoughtful, you can program around this locking architecture in SQL Server, but most Internet service operators would rather just install Oracle than train their programmers to think more carefully about concurrency.
Time Publisher Public Web Application 12:00 PM Starts a 90-minute query summarizing usage for preceding year -- 12:30 PM usage summary continues to chug away User #356712 updates email address from "joe@foobar.com" to "joe@yahoo.com" 12:45 PM usage summary arrives at User #356712; Oracle reaches into rollback segment and pulls out "joe@foobar.com" for the report, since that's what the value was at 12:30 PM -- 1:30 PM usage summary report completes --
The open-source purist's only realistic choice for an RDBMS is PostgreSQL, available from www.postgresql.org. In some ways, PostgreSQL has more advanced features than any commercial RDBMS, and it has an Oracle-style multi-version concurrency system. PostgreSQL is easy to install and administer, but is not used by operators of large services because there is no way to build a truly massive PostgreSQL installation or one that can tolerate hardware failures.
Most of the SQL examples in this book will use Oracle syntax. This is partly because Oracle is the world's most popular RDBMS, but mostly because Oracle is what we had running at MIT when we started working in this area back in 1994 and therefore we have whole file systems full of Oracle code. Problem set supplements (see end of chapter) may contain translations for ANSI SQL databases such as Microsoft SQL Server and PostgreSQL.
That said, let us put in a kind word for scripting languages. If you need to write some heavy-duty abstractions you can always do those in Java running inside Oracle or C# running within Microsoft .NET. But for your presentation layer, i.e., individual pages, don't overlook the advantages of using simpler and terser languages such as Perl, Tcl, and Visual Basic.
CheckForContestAdminAuthority and instruct your script
authors to include a call to this procedure in each of the fifteen admin
scripts. You've still got fifteen copies of some code: one IF statement,
one procedure call, and a call to an error message procedure if
CheckForContestAdminAuthority returns "unauthorized".
But the SQL query occurs only in one place and can be updated
centrally.
The main problem with this approach is not the fifteen copies of the IF statement and its consequents. The problem is that inevitably one of the script authors will forget to include the check. So your site has a security hole. You close the hole and eliminate fourteen copies of the IF statement by installing the code as a server filter. Note that for this to work the filter mechanism must include an API for aborting service of the requested page. Your filter needs to be able to tell the Web server "Don't proceed with serving the user with the script or document requested".
You need a Web programming environment powerful enough that you can build something that we'll call a request processor. This program looks at an incoming abstract URL, e.g., "one-topic", and follows the following logic:
Connect to your server from a Web browser, using only the host name. For the rest of this problem set, we're going to assume that your hostname is "yourhostname.com". Verify that when you request http://yourhostname.com your customized page is presented. If you get a directory listing instead your Web server is probably not configured to look for index files named "index.html"; you'll have to reconfigure your server. Now use an HTML validator to make sure that your HTML is legal (see Yahoo's directory of HTML validators at http://dir.yahoo.com/Computers_and_Internet/Data_Formats/HTML/Validation_and_Checkers/ for a list of programs and services).
You've made at least two requests from your Web server now. These will have been logged in the server access log. Find it in the file system and verify that the times and files requested shown make sense to you.
Put a file in the directory so that it is accessible at http://yourhostname.com/basics/my-first-program (if you haven't yet figured out how to implement abstract URLs, this may be "my-first-program.pl" or "my-first-program.asp" or similar).
When we visit http://yourhostname.com/basics/my-first-program we should see the current time wrapped in a legal HTML page of some sort, signed with your email address.
Add some code that will generate a divide-by-zero error to your program. Find and visit the server error log to see how this error is communicated to you. With some execution environments, it may be possible to have the error message and stack backtrace presented to you in the browser window when the error occurs. If you can configure your server thusly, you'll find that debugging goes much faster this semester. If not, make sure that you know how to quickly display the latest errors. On a Unix machine you'd use the command "tail -f error.log" in a shell or "M-x revert-buffer" in an Emacs editor visiting the error log.
Just before the code that generates the divide-by-zero error, add a line of code to write the following message into the error log: "About to divide by zero". Request http://yourhostname.com/basics/my-first-program from a browser again and then visit the error log to verify that your "About to divide by zero" statement precedes the actual error.
Make this service work on your server. Note that this will involve (1) learning a bit about HTML forms, (2) following the "view the source code" link on the results page at photo.net and pulling the mathematical formula out of the program there, (3) parking a static .html file containing the form on your server at /basics/lens-calculator, and (4) parking a program to process the form at /basics/lens-calculator-2.
(Note the naming convention above. When possible this semester we'd like you to adhere to the idea that a script that processes a form at "foobar" is found at "foobar-2". If there is a pipeline of steps that a user must follow, we like to see them at "foobar", "foobar-2", "foobar-3", etc.)
Hints: you'll want to deliver your script and any template file, if
applicable, with a MIME type of "text/plain". This way the receiving
browser won't try to render the HTML source. Some Web browsers are
super aggressive and try to render anything that looks like HTML, even
if it comes through without the text/html MIME type. An alternative
approach that works with such browsers is to quote all of your HTML by
replacing < with <,
> with >, and &
with &, then wrap source code in a <PRE> tag.
Figure 2.3: The Bill Gates Personal Wealth Clock. This program queries a public stock quote server to find the price of Microsoft stock and the U.S. Census Bureau's server for the current U.S. population, then combines the numbers on one page.
There are several interesting things about this program, which was built by one of the authors in 1995. One is that it was enabled by the existence of a procedure built into AOLserver that went out and grabbed a page from the wider Internet,ns_httpget. This
enabled the entire project to be completed in one hour. Engineering
is all about cost. If building this little application would have
required several days of work it probably would not have been done. A
second item worth noting is that the program has required substantial
maintenance over the years, far exceeding its initial development
cost. The program relies on using regular expressions to pull data
out of HTML pages that are designed for human eyes. As the publishers
of the underlying data sources have changed their HTML formatting over
the years, these regular expressions have had to be updated.
The final point worth mentioning about this program is that part of the hour of coding went into building a general-purpose caching or memoization system to record the results of evaluating any Tcl expression in a global variable. Why? It seemed like bad netiquette to write a program that had the potential to impose an unreasonable load on the Census Bureau and stock quote servers. Also, in the event that the Wealth Clock became popular it would be asking the underlying servers several times a second for the same data. Lastly it seemed that users shouldn't have to wait for the two subsidiary pages to be fetched if they didn't need up-to-the-minute data. With the complete HTML page stored in a global variable, it is available from AOLserver's virtual memory space and can be accessed much faster than even a static file. Users who want a real-time answer can demand one with an extra mouse click. The calculation performed for them then updates the cache for casual users.
The caching mechanism might sound like overengineering but from time to time the Wealth Clock would be linked to from extremely popular news sites and receive several requests per second. The ability to handle a reasonably high load like that, back in the mid-1990s, without an enormous server farm was rather rare. Had those requests been passed directly through to the Census Bureau, for example, the entire service would have slowed to a crawl.
The source code for this program is available at http://philip.greenspun.com/seia/examples-basics/wealth-clock.tcl.txt and may prove helpful in doing the next exercise.
We suggest querying barnesandnoble.com and www.powells.com. Your
program should be robust to timeouts, errors at the foreign sites, and
network problems. In other words, in no situation should your user
ever get a "Server Error 500" page. To ensure this you'll have to
learn about exception handling in your chosen language. In Java, for
example, you'll want to use try and catch.
Test your program with the following ISBNs: 0590353403,
0140260404, 0679762906, 1588750019.
Try adding more bookstores, but you may have trouble getting them to work. For example, amazon.com and wordsworth.com tend to respond with a 302 redirect if the client doesn't give them a session ID in the query.
Extra credit: Which of the preceding books states that "The obvious mathematical breakthrough would be development of an easy way to factor large prime numbers"?
"Remember that it is a mistake to compare Harry Potter to Shakespeare... That's because Harry Potter is a fictional character whereas Shakespeare was an author. What you really ought to be doing is comparing J.K. Rowling to Shakespeare" -- Jin S. Choi.
On Unix, the most convenient way to drive Oracle is generally from within Emacs, assuming you're already an Emacs user. Type "M-x shell" to get a Unix shell. Type "M-x rename-buffer" to rename the shell to "sql-shell" so that you can always type "M-x shell" again and get an operating system shell. In the sql-shell buffer type "sqlplus" to start SQL*Plus, the Oracle shell client. If you're using Windows, look for the program "SQLPLUS.EXE" or "PLUS80.EXE".
SQL*Plus will prompt you for a username and password. If you're using a school-supplied development server, you may need to get these from your TA. If you set up the RDBMS yourself, you might need to create a new tablespace and user before you can do this exercise.
Type the following at the SQL*Plus prompt to create a table for keeping track of the classes you're taking this semester:
create table my_courses (
course_number varchar(20)
);
Note that you have to end your SQL commands with a semicolon in
SQL*Plus. These are not part of the SQL language and you shouldn't
use these when writing SQL in your Web scripts.
Insert a few rows, e.g.,
insert into my_courses (course_number) values ('6.171');
See what you've got:
select * from my_courses;
Commit your changes:
commit;
Note that until you typed this COMMIT, another connected database user
wouldn't have been able to see the row that you inserted. "Connected
database user" includes the Web server. A common source of student
consternation with Oracle is that they've inserted information with
SQL*Plus and neglected to COMMIT. The new information does not appear
on any of their Web pages, and they tear their hair out debugging. Of
course nothing is wrong with their scripts. It is just that the ACID
guarantees mean that the Web server sees a different view of the database
than the user who is in the middle of a transaction.
Your view of the table shouldn't change after a COMMIT, but maybe check again:
select * from my_courses;
One of the main benefits of using an RDBMS is persistence.
Everything that you create stays around even after you log out.
Normally, that's a good thing, but in this case you probably want to
clean up after your experiment:
drop table my_courses;
Quit SQL*Plus with the quit command.
If your instructors are being nice to you, they'll already have translated this pseudo-code into something that works with the infrastructure you're using at your school. If not, you'll have to translate it yourself, along with http://philip.greenspun.com/seia/examples-basics/quotation-add-pseudo-code.txt . Park your finished program at /basics/quotations (plus a file extension if you must). Add a hyperlink from your site index page to this service.
Use the form on the Web page to manually add some quotations. If you don't feel inspired to surf, here are a few to get you going:
Return to your RDBMS shell client (e.g., SQL*Plus for Oracle) and
select * from the table to see that your quotation has
been inserted into the table.
In your RDBMS shell client, insert a quotation with some hand-coded
SQL. To see the form of the SQL INSERT command you should use, examine
the code on the page quotation-add. After creating this new table
row, do select * again, and you should now see two rows.
Hint: Don't forget that SQL quotes strings using single quotes, not double quotes .
Now reload the quotations URL from your Web browser. If
you don't see your new quotation here, that's because you didn't type
"commit;" at SQL*Plus and the Web server is being protected from
seeing the unfinished transaction.
lock table via a sequencelock table
like '%foo%' and SQL's UPPER and LOWER functions.
Hint 1: It is possible to build this system using an ID cookie for the browser and keeping the set of killed quotations in the RDBMS. However, if you're not going to allow users to log in and claim their profile, there really isn't much point in keeping data on the server.
Hint 2: It isn't strictly copacetic with the cookie spec, but browsers accept cookie values containing spaces. So you can store the killed quotations as a space-separated list if you like.
Hint 3: Don't filter the quotations in your Web script. It is generally a sign of incompetent programming when you query more data from the RDBMS than you're going to display to the end-user. SQL is a very powerful query language. You can use the NOT IN feature to exclude a list of quotations.
Here's what we need in order to cooperate:
We'll format the quotations using XML, a conventional notation for
describing structured data. XML structures consist of data strings
enclosed in HTML-like tags of the form <foo> and
</foo>, describing what kind of thing the data is
supposed to be.
Here's an informal example, showing the structure we'll use for our quotations:
<quotations>
<onequote>
<quotation_id>1</quotation_id>
<insertion_date>2004-01-26</insertion_date>
<author_name>Britney Spears</author_name>
<category>Pop Musician Leisure Activities</category>
<quote>I shop, go to movies, soak up the sun when possible and go out to eat.</quote>
</onequote>
<onequote>
.. another row from the quotations table ...
</onequote>
... some more rows
</quotations>
Notice that there's a separate tag for each column in our SQL data model:
<quotation_id>
<insertion_date>
<author_name>
<category>
<quote>
There's also a "wrapper" tag that identifies each row as a
<onequote> structure, and an outer wrapper that
identifies a sequence of <onequote> structures as a
<quotations> document.
Our DTD will start with a definition of the quotations
tag:
<!ELEMENT quotations (onequote)+>
This says that the quotations element must contain at
least one occurrence of onequote but may contain more
than one. Now we have to say what constitutes a legal
onequote element:
<!ELEMENT onequote (quotation_id,insertion_date,author_name,category,quote)>
This says that the sub-elements, such as quotation_id must
each appear exactly once and in the specified order. Now we have to
define an XML element that actually contains something other than
other XML elements:
<!ELEMENT quotation_id (#PCDATA)>
This says that whatever falls between <quotation_id>
and </quotation_id> is to be interpreted as raw
characters rather than as containing further tags (PCDATA stands for
"parsed character data").
Here's our complete DTD:
<!-- quotations.dtd -->
<!ELEMENT quotations (onequote)+>
<!ELEMENT onequote (quotation_id,insertion_date,author_name,category,quote)>
<!ELEMENT quotation_id (#PCDATA)>
<!ELEMENT insertion_date (#PCDATA)>
<!ELEMENT author_name (#PCDATA)>
<!ELEMENT category (#PCDATA)>
<!ELEMENT quote (#PCDATA)>
You will find this extremely useful... Hey, actually you won't find
this DTD useful at all for completing this part of the problem set.
The only situation in which a DTD is useful is when feeding documents
to an XML parser because then the parser can automatically tokenize each
XML document. For implementing your quotations-xml page, you will
only need to look at the informal example.
The meat of this exercise: Write a script that queries the
quotations table, produces an XML document in the
preceding form, and returns it to the client with a MIME type of
"application/xml". Place this in the file system at
/basics/quotations-xml, so that other users can retrieve the data by
visiting that agreed-upon URL.
/basics/quotations-xml from another student's
server.
quotation_id. (You
don't want keys from the foreign server conflicting with what is
already in your database.)
Hint: You can set up a temporary table using create table
quotations_temp as select * from quotations and then drop it
after you're done debugging, so that you don't mess up your own
quotations database.
You are not expected to write an XML parser as part of this exercise. You will either use a general-purpose XML parser or your TAs will give you a simple program that is capable only of parsing this particular format. If you aren't getting any help from your TAs and you're using Oracle, keep in mind that the Oracle RDBMS has extensive built-in support for processing XML. Read the Oracle documentation, notably the Oracle XML DB Developer's Guide - Oracle XML DB. If you're using Java or Perl there are plenty of free open-source XML parsers available. The Microsoft .NET Framework Class Library contains classes that provide a full set of XML tools.
It is your professional obligation to other programmers to take responsibility for your source code. It is your professional obligation to end-users to take responsibility for their experience with your program.
To facilitate turning in your problem set, keep a text file transcript of relevant parts of your database session at http://yourhostname.com/basics/db-exercises.txt.
create table my_stocks (
symbol varchar(20) not null,
n_shares integer not null,
date_acquired date not null
);
sqlldr shell command on Unix to invoke
SQL*Loader to slurp up your tab-separated file into the
my_stocks table
stock_prices with three columns: symbol,
quote_date, price. Within this one statement, fill the table you're creating
with one row per symbol in
my_stocks. The date and price columns should be filled
with the current date and a nominal price. Hint:
select symbol, sysdate as quote_date, 31.415 as price from my_stocks;
.
create table newly_acquired_stocks (
symbol varchar(20) not null,
n_shares integer not null,
date_acquired date not null
);
insert into ... select ... statement
(with a WHERE clause appropriate to your sample data), copy about half
the rows from my_stocks into newly_acquired_stocks
my_stocks and
stock_prices, produce a report showing symbol, number of
shares, price per share, and current value.
my_stocks. Rerun your query from the
previous exercise. Notice that your new stock does not appear in the
report. This is because you've JOINed them with the constraint that
the symbol appear in both tables.
Modify your statement to use an OUTER JOIN instead so that you'll get a complete report of all your stocks, but won't get price information if none is available.
ASCII function will be helpful.
stock_prices
to set each stock's value to whatever is returned by this PL/SQL
procedure
n_shares * price for
each stock). You'll want to define your JOIN from DB Exercise 3
(above) as a cursor and then use the PL/SQL Cursor FOR LOOP facility.
Hint: when you're all done, you can run this procedure from SQL*Plus
with select portfolio_value() from dual;.
date_acquired set to sysdate)
select ... group by ... query from my_stocks to
produce a report of symbols and total shares held
select ... group by ... query JOINing with
stock_prices to produce a report of symbols and total
value held per symbol
select ... group by ... having ... query to produce a report of
symbols, total shares held, and total value held per symbol
restricted to symbols in which you have at least two blocks of
shares (i.e., the "winners")
stocks_i_like that encapsulates the final query.
Given an established development environment, the exercises in this chapter take between six and twelve hours for MIT students working in a lab where teaching assistants are available and possibly as long as twenty hours for those working by themselves.