
|
|
Chapter 13: Interfacing a Relational Database to the Webby Philip Greenspun, part of Philip and Alex's Guide to Web Publishing |
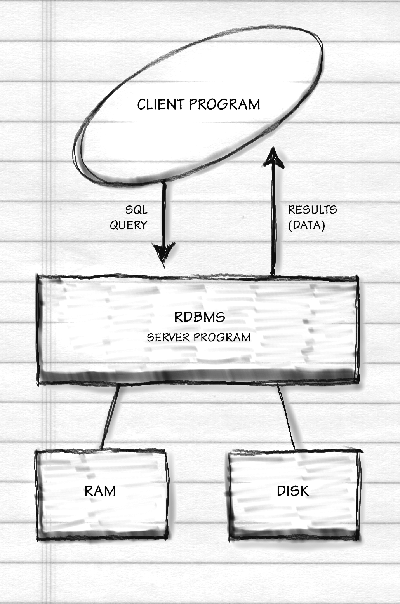
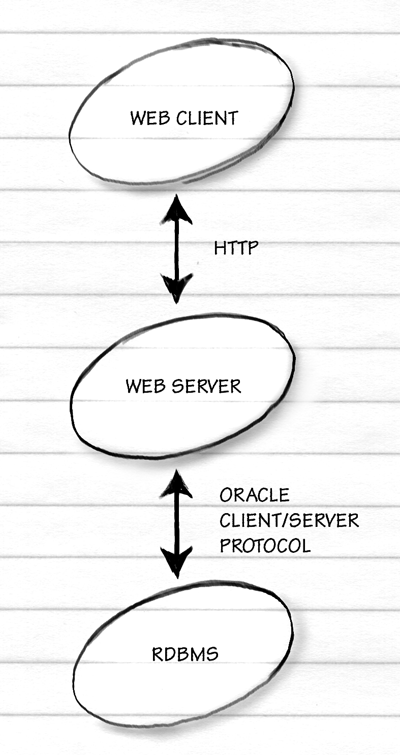
For a properly engineered RDBMS-backed Web site, the RDBMS
client is the Web server program, e.g., AOLserver.
The user types something into a form on a Web client (e.g., Netscape
Navigator) and that gets transmitted to the Web server which has
an already-established connection to an RDBMS server
(e.g., Oracle). The data then go back from the RDBMS server to the
RDBMS client, the Web server, which sends them back to the Web client:
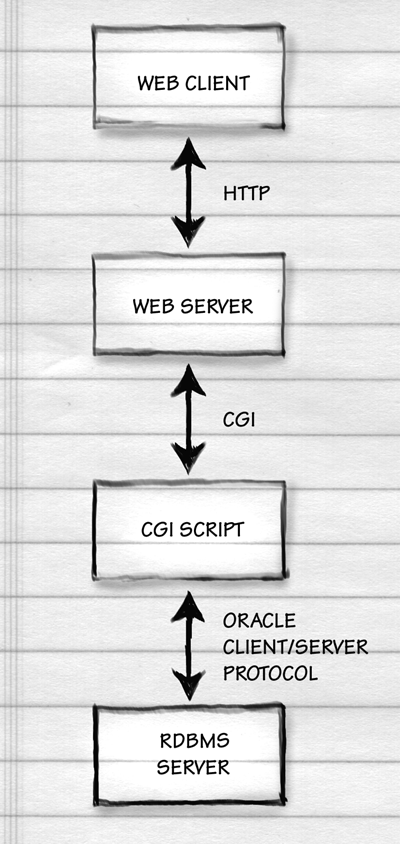
Does this system sound complicated and slow? Well, yes it is, but not as
slow as the ancient method of building RDBMS-backed Web sites. In
ancient times, people used CGI scripts. The user would click on the
"Submit" button in his Web client (e.g., Netscape Navigator)
causing the form to be transmitted to the Web server (e.g., NCSA
1.4). The Web server would fork off a CGI script, starting up a new
operating system process. Modern computers are very fast, but think
about how long it takes to start up a word processing program versus
making a change to a document that is already open. Once running, the
CGI program would immediately ask for a connection to the RDBMS, often
resulting in the RDBMS forking off a server process to handle the new
request for connection. The new RDBMS server process would ask for a
username and password and authenticate the CGI script as a user. Only
then would the SQL transmission and results delivery commence. A lot of
sites are still running this way in 1998 but either they aren't popular
or they feel unresponsive. Here's a schematic:
 The Web-server-as-database-client software architecture is the fastest
currently popular Web site architecture. The Web server program
maintains a pool of already-open connections to one or more RDBMS
systems. You write scripts that run inside the Web server program's
process instead of as CGI processes. For each URL requested, you save
The Web-server-as-database-client software architecture is the fastest
currently popular Web site architecture. The Web server program
maintains a pool of already-open connections to one or more RDBMS
systems. You write scripts that run inside the Web server program's
process instead of as CGI processes. For each URL requested, you save
If you are building a richly interactive site and want the ultimate in user responsiveness, then client-side Java is the way to go. You can write a Java applet that, after a painful and slow initial download, starts running inside the user's Web client. The applet can make its own TCP connection back to the RDBMS, thus completely bypassing the Web server program. The problems with this approach include security, licensing, performance, and compatibility.
The client/server RDBMS abstraction barrier means that if you're going to allow a Java applet that you distribute to connect directly to your RDBMS, then in effect you're going to permit any program on any computer anywhere in the world to connect to your RDBMS. To deal with the security risk that this presents, you have to create a PUBLIC database user with a restricted set of privileges. Database privileges are specifiable on a set of actions, tables, and columns. It is not possible to restrict users to particular rows. So in a classified ad system, if the PUBLIC user has enough privileges to delete one row, then a malicious person could easily delete all the rows in the ads table.
The magnitude of the licensing problem raised by having Java applets connect directly to your RDBMS depends on the contract you have with your database management system vendor and the vendor's approach to holding you to that contract. Under the classical db-backed Web site architecture, the Web server might have counted as one user even if multiple people were connecting to the Web site simultaneously. Certainly, it would have looked like one user to fancy license manager programs even if there was legal fine print saying that you have to pay for the multiplexing. Once you "upgrade to Java," each Java applet connecting to your RDBMS will definitely be seen by the license manager program as a distinct user. So you might have to pay tens of thousands of dollars extra even though your users aren't really getting anything very different.
A standard RDBMS will fork a server process for each connected database client. Thus if you have 400 people playing a game in which each user interacts with a Java applet connected to Oracle, your server will need enough RAM to support 400 Oracle server processes. It might be more efficient in terms of RAM and CPU to program the Java applets to talk to AOLserver Tcl scripts via HTTP and let AOLServer multiplex the database resource among its threads.
The last problem with a Java applet/RDBMS system is the most obvious: Users without Java-compatible browsers won't be able to use the system. Users with Java-compatible browsers behind corporate firewall proxies that block Java applet requests will not be able to use the system. Users with Java-compatible browsers who successfully obtain your applet may find their machine (Macintosh; Windows 95) or browser process (Windows NT; Unix) crashing.
 A variant of the Java-connects-directly-to-the-RDBMS architecture is
Java applets running an Object Request Broker (ORB) talking to a
Common Object Request Broker Architecture (CORBA) server via the Internet
Inter-ORB Protocol (IIOP). The user downloads a Java applet. The Java
applet starts up an ORB. The ORB makes an IIOP request to get to your
server machines's CORBA server program. The CORBA server requests an
object from the server machine's ORB. The object, presumably some
little program that you've written, is started up by the ORB and makes
a connection to your RDBMS and then starts streaming the data back to
the client.
A variant of the Java-connects-directly-to-the-RDBMS architecture is
Java applets running an Object Request Broker (ORB) talking to a
Common Object Request Broker Architecture (CORBA) server via the Internet
Inter-ORB Protocol (IIOP). The user downloads a Java applet. The Java
applet starts up an ORB. The ORB makes an IIOP request to get to your
server machines's CORBA server program. The CORBA server requests an
object from the server machine's ORB. The object, presumably some
little program that you've written, is started up by the ORB and makes
a connection to your RDBMS and then starts streaming the data back to
the client.
CORBA is the future. CORBA is backed by Netscape, Oracle, Sun, Hewlett-Packard, IBM, and 700 other companies (except Microsoft, of course). CORBA is so great, its proponents proudly proclaim it to be . . . "middleware":
"The (ORB) is the middleware that establishes the client-server relationships between objects. Using an ORB, a client can transparently invoke a method on a server object, which can be on the same machine or across a network. The ORB intercepts the call and is responsible for finding an object that can implement the request, pass it the parameters, invoke its method, and return the results. The client does not have to be aware of where the object is located, its programming language, its operating system, or any other system aspects that are not part of an object's interface. In so doing, the ORB provides interoperability between applications on different machines in heterogeneous distributed environments and seamlessly interconnects multiple object systems."
-- http://www.omg.org/
The basic idea of CORBA is that every time you write a computer program you also write a description of the computer program's inputs and outputs. Modern business managers don't like to buy computer programs anymore so we'll call the computer program an "object". Technology managers don't like powerful computer languages such as Common Lisp so we'll write the description in a new language: Interface Definition Language (IDL).
Suppose that you've written an object (computer program) called
find_cheapest_flight_to_paris and declared that it can take
methods such as quote_fare with arguments of city name and
departure date and book_ticket with the same arguments plus
credit card number and passenger name.
Now a random computer program (object) out there in Cyberspace can go
hunting via ORBs for an object named
find_cheapest_flight_to_paris. The foreign object will
discover the program that you've written, ask for the legal
methods and arguments, and start using your program to find the cheapest
flights to Paris.
The second big CORBA idea is the ability to wrap services such as transaction management around arbitrary computer programs. As long as you've implemented all of your programs to the CORBA standard, you can just ask the Object Transaction Service (OTS) to make sure that a bunch of methods executed on a bunch of objects all happen or that none happen. You won't have to do everything inside the RDBMS anymore just because you want to take advantage of its transaction system.
 Given the quality of the C code inside the Unix and Windows NT operating
systems and the quality of the C code inside RDBMS products, it is
sometimes a source of amazement to me that there is even a single
working RDBMS-backed Web site on the Internet. What if these sites also
had to depend on two ORBs being up and running? Netscape hasn't yet
figured out how to make a browser that can run a simple Java animation
without crashing, but we're supposed to trust the complicated Java ORB
that they are putting into their latest browsers?
Given the quality of the C code inside the Unix and Windows NT operating
systems and the quality of the C code inside RDBMS products, it is
sometimes a source of amazement to me that there is even a single
working RDBMS-backed Web site on the Internet. What if these sites also
had to depend on two ORBs being up and running? Netscape hasn't yet
figured out how to make a browser that can run a simple Java animation
without crashing, but we're supposed to trust the complicated Java ORB
that they are putting into their latest browsers?
Actually I'm being extremely unfair. I've never heard, for example, of a bug in a CORBA Concurrency Control Service, used to manage locks. Perhaps, though, that is because eight years after the CORBA standard was proposed, nobody has implemented a Concurrency Control Service. CORBA circa 1998 is a lot like an Arizona housing development circa 1950. The architect's model looks great. The model home is comfortable. You'll have water and sewage hookups real soon now.
 Assume for the sake of argument that all the CORBA middleware actually
worked. Would it usher in a new dawn of reliable, high-performance
software systems? Yes, I guess so, as long as your idea of new dawn
dates back to the late 1970s.
Assume for the sake of argument that all the CORBA middleware actually
worked. Would it usher in a new dawn of reliable, high-performance
software systems? Yes, I guess so, as long as your idea of new dawn
dates back to the late 1970s.
Before the Great Microsoft Technology Winter, there were plenty of systems that functioned more or less like CORBA. Xerox Palo Alto Research Center produced SmallTalk and the InterLISP machines. MIT produced the Lisp Machine. All of these operating systems/development environments supported powerful objects. The objects could discover each other. The objects could ask each other what kinds of methods they provided. Did that mean that my objects could invoke methods on your objects without human intervention?
No. Let's go back to our find_cheapest_flight_to_paris
example. Suppose the foreign object is looking for
find_cheap_flight_to_paris. It won't find your perfectly
matching object because of the slight difference in naming. Or suppose
the foreign object is looking for find_cheapest_flight and
expects to provide the destination city in an argument to a
method. Again, your object can't be used.
That was 1978, though. Isn't CORBA an advancement over Lisp and SmallTalk? Sure. CORBA solves the trivial problem of objects calling each other over computer networks rather than from within the same computer. But CORBA ignores the serious problem of semantic mismatches. My object doesn't get any help from CORBA in explaining to other objects that it knows something about airplane flights to Paris.
This is my personal theory for why CORBA has had so little practical impact during its eight-year life.
 Maybe CORBA is nothing special, but wouldn't it be better to implement a
Web service as a bunch of encapsulated objects with advertised methods
and arguments? After all, object-oriented programming is a useful tool
for building big systems.
Maybe CORBA is nothing special, but wouldn't it be better to implement a
Web service as a bunch of encapsulated objects with advertised methods
and arguments? After all, object-oriented programming is a useful tool
for building big systems.
The simple answer is that a Web service already is an encapsulated object with advertised methods and arguments. The methods are the legal URLs, "insert-msg.tcl" or "add-user.tcl" for example. The arguments to these methods are the form-variables in the pages that precede these URLs.
A more balanced answer is that a Web service is already an encapsulated object but that its methods and arguments are not very well advertised. We don't have a protocol whereby Server A can ask Server B to "please send me a list of all your legal URLs and their arguments." Hence, CORBA may one day genuinely facilitate server-to-server communication. For the average site, though, it isn't clear whether the additional programming effort over slapping something together in AOLserver Tcl, Apache mod_perl, or Microsoft ASP is worth it. You might decide to completely redesign your Web service before CORBA becomes a reality.
In concluding this CORBA-for-Cavemen discussion, it is worth noting that the issues of securing your RDBMS are the same whether you are using a classical HTTP-only Web service architecture or CORBA.
 I hope that we have spent most of our time in this book thinking about
how to design Web services that will be popular and valued by users. I
hope that I've also conveyed some valuable lessons about achieving high
performance and reliability. However, a responsive, reliable, and
popular Web server that is delivering data inserted by your enemies
isn't anything to e-mail home about. So it is worth thinking about
security occasionally. I haven't written anything substantial about
securing a standard Windows NT or Unix server. I'm not an expert in this
field, there are plenty of good books on the subject, and ultimately it
isn't possible to achieve perfect security so you'd better have a good
set of backup tapes. However, running any kind of RDBMS raises a bunch
of new security issues that I have spent some time thinking about
so let's look at how Carrie Cracker can get into your database.
I hope that we have spent most of our time in this book thinking about
how to design Web services that will be popular and valued by users. I
hope that I've also conveyed some valuable lessons about achieving high
performance and reliability. However, a responsive, reliable, and
popular Web server that is delivering data inserted by your enemies
isn't anything to e-mail home about. So it is worth thinking about
security occasionally. I haven't written anything substantial about
securing a standard Windows NT or Unix server. I'm not an expert in this
field, there are plenty of good books on the subject, and ultimately it
isn't possible to achieve perfect security so you'd better have a good
set of backup tapes. However, running any kind of RDBMS raises a bunch
of new security issues that I have spent some time thinking about
so let's look at how Carrie Cracker can get into your database.
Before Carrie can have a data modeling language (INSERT, UPDATE, DELETE) party with your data, she has to
 One of the easiest ways to prevent direct network connections to your
RDBMS is to use a traditional RDBMS in a non-traditional manner. If you
install Oracle8, you'd have to spend a whole day reading SQL*Net
manuals before you can think about setting up networking. The only
programs that will be able to connect to your new Oracle server are
programs running on the RDBMS server itself. This would be useless in
an insurance company where clerks at 1000 desktops need to connect
to Oracle. But for many Web sites, there is no reason why you can't run
the database and Web server on the same box. The database will consume
95 percent of your resources. So if a computer is big enough to run Oracle,
you can just add a tiny bit of CPU and memory and have a maximally
reliable site (since you only have to keep one computer up and running).
One of the easiest ways to prevent direct network connections to your
RDBMS is to use a traditional RDBMS in a non-traditional manner. If you
install Oracle8, you'd have to spend a whole day reading SQL*Net
manuals before you can think about setting up networking. The only
programs that will be able to connect to your new Oracle server are
programs running on the RDBMS server itself. This would be useless in
an insurance company where clerks at 1000 desktops need to connect
to Oracle. But for many Web sites, there is no reason why you can't run
the database and Web server on the same box. The database will consume
95 percent of your resources. So if a computer is big enough to run Oracle,
you can just add a tiny bit of CPU and memory and have a maximally
reliable site (since you only have to keep one computer up and running).
Suppose that you must install SQL*Net to let folks inside your organization talk directly to Oracle, or that you're using a newer-style RDBMS (e.g., Solid) that is network-centric. By installing the RDBMS, you've opened a huge security hole: a program listening on a TCP port and happy to accept connections from anywhere on the Internet.
A remarkably incompetent publisher would be
Is anyone out there on the Internet really this incompetent? Sure! I have done at least one consulting job for a company whose Web server had been set up and left like this for months. The ISP was extremely experienced with both the Web server program and the RDBMS being used. The ISP was charging my client thousands of dollars per month. Was this reasonably popular site assaulted by the legions of crackers one reads about in the dead trees media? No. Nobody touched their data. The lesson: Don't spend your whole life worrying about security.
However, you'll probably sleep better if you spend at least a little time foiling Carrie Cracker. The easiest place to start is with the username/password pairs. You want to set these to something hard to guess. Unfortunately, these aren't super secure because they often must be stored as clear text in CGI scripts or cron jobs that connect to the database. Then anyone who gets a Unix username/password pair can read the CGI scripts and collect the database password. On a site where the Web server itself is the database client, the Web server configuration files will usually contain the database password in clear text. This is only one file so it is easy to give it meager permissions but anyone who can become root on your Unix box can certainly read it.
A worthwhile parallel approach is to try to prevent Carrie from connecting to the RDBMS at all. You could just configure your RDBMS to listen on different ports from the default. Carrie can't get in anymore by just trying port 7599 because she saw the little "backed by Sybase" on your home page and knows that Sybase will probably be listening there. Carrie will have to sweep up and down the port numbers until your server responds. Maybe she'll get bored and try someone else's site.
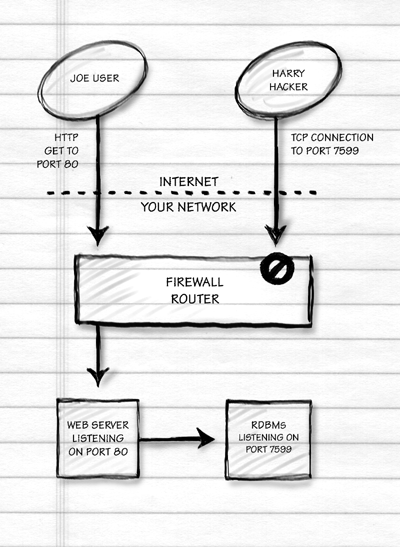
A much more powerful approach is moving the database server behind a firewall. This is necessary mostly because RDBMSes have such lame security notions. For example, it should be possible to tell the RDBMS, "Only accept requests for TCP connections from the following IP addresses . . .". Every Web server program since 1992 has been capable of this. However, I'm not aware of any RDBMS vendor who has figured this out. They talk the Internet talk, but they walk the intranet walk.
Because Oracle, Informix, and Sybase forgot to add a few lines of code to their product, you'll be adding $10,000 to your budget and buying a firewall computer. This machine sits between the Internet and the database server. Assuming your Web server is outside the firewall, you program the firewall to "not let anyone make a TCP connection to port 7599 on the database server except 18.23.0.16 [your Web server]." This works great until someone compromises your Web server. Now they are root on the computer that the firewall has been programmed to let connect to the database server. So they can connect to the database.
Oops.
So you move your Web server inside the firewall, too. Then you program
the firewall to allow nobody to connect to the database server
for any reason. The only kind of TCP connection that will be allowed
will be to port 80 on the Web server (that's the default port for
HTTP). Now you're reasonably secure:
# send basic text/html headers back to the client
ns_write "HTTP/1.0 200 OK
MIME-Version: 1.0
Content-Type: text/html
"
# write the top of the page
# note that we just put static HTML in a Tcl string and then
# call the AOLserver API function ns_write
ns_write "<head>
<title>Entire Mailing List</title>
</head>
<body>
<h2>Entire Mailing List</h2>
<hr>
<ul>
"
# get an open database from the AOLserver
# and set the ID of that connection to the local variable DB
set db [ns_db gethandle]
# open a database cursor bound to the local variable SELECTION
# we want to read all the columns (*) from the mailing_list table
set selection [ns_db select $db "select * from mailing_list
order by upper(email)"]
# loop through the cursor, calling ns_db getrow to bind
# the Tcl local variable SELECTION to a set of values for
# each row; it will return 0 when there are no more rows
# in the cursor
while { [ns_db getrow $db $selection] } {
# pull email and name out of SELECTION
set email [ns_set get $selection email]
set name [ns_set get $selection name]
ns_write "<li><a href=\"mailto:$email\">$email</a> ($name)\n"
}
ns_write "</ul>
<hr>
<address><a href=\"mailto:philg@mit.edu\">philg@mit.edu</a></address>
</body>
"Let's try something similar in Oracle Application Server. We're going to use PL/SQL, Oracle's vaguely ADA-inspired procedural language that runs inside the server process. It is a safe language and an incorrect PL/SQL program will usually not compile. If an incorrect program gets past the compiler, it will not run wild and crash Oracle unless there is a bug in the Oracle implementation of PL/SQL. This PL/SQL program is from a bulletin board system. It takes a message ID argument, fetches the corresponding message from a database table, and writes the content out in an HTML page. Note that in Oracle WebServer 2.0 there is a 1-1 mapping between PL/SQL function names and URLs. This one will be referenced via a URL of the following form:
http://www.greedy.com/public/owa/bbd_fetch_msg
-- this is a definition that we feed directly to the database
-- in an SQL*PLUS session. So the procedure definition is itself
-- an extended SQL statement. The first line says I'm a Web page
-- that takes one argument, V_MSG_ID, which is a variable length
-- character string
create or replace procedure bbd_fetch_msg ( v_msg_id IN varchar2 )
AS
-- here we must declare all the local variables
-- the first declaration reaches into the database and
-- makes the local variable bboard_record have
-- the same type as a row from the bboard table
bboard_record bboard%ROWTYPE;
days_since_posted integer;
age_string varchar2(100);
BEGIN
-- we grab all the information we're going to need
select * into bboard_record from bboard where msg_id = v_msg_id;
-- we call the Oracle function "sysdate" just as we could
-- in a regular SQL statement
days_since_posted := sysdate - bboard_record.posting_time;
-- here's something that you can't have in a declarative
-- language like SQL... an IF statement
IF days_since_posted = 0 THEN
age_string := 'today';
ELSIF days_since_posted = 1 THEN
age_string := 'yesterday';
ELSE
age_string := days_since_posted || ' days ago';
END IF;
-- this is the business end of the procedure. We
-- call the Oracle WebServer 2.0 API procedure htp.print
-- note that the argument is a big long string produced
-- by concatenating (using the "||" operator) static
-- strings and then information from bboard_record
htp.print('<html>
<head>
<title>' || bboard_record.one_line || '</title>
</head>
<body bgcolor=#ffffff text=#000000>
<h3>' || bboard_record.one_line || '</h3>
from ' || bboard_record.name || '
(<a href="mailto:' || bboard_record.email || '">'
|| bboard_record.email || '</a>)
<hr>
' || bboard_record.message || '
<hr>
(posted '|| age_string || ')
</body>
</html>');
END bbd_fetch_msg;The first thing to note in this program is that we choose "v_msg_id" instead of the obvious "msg_id" as the procedure argument. If we'd used "msg_id", then our database query would have been
select * into bboard_record from bboard where msg_id = msg_id;
select * from bboard where msg_id = msg_id;
Another thing to note is that it would be tough to rewrite this
procedure to deal with a multiplicity of database tables. Suppose you
decided to have a separate table for each discussion group. So you had
photo_35mm_bboard and
photo_medium_format_bboard tables. Then you'd just add a
v_table_name argument to the procedure. But what about
these local variable declarations?
bboard_record bboard%ROWTYPE;
bboard_record v_table_name%ROWTYPE;
You're not in Kansas anymore and you're not Web scripting either. This is programming. You're declaring variables. You're using a compiler that will be all over you like a cheap suit if you type a variable name incorrectly. Any formally trained computer scientist should be in heaven. Well, yes and no. Strongly typed languages like ADA and Pascal result in more reliable code. This is great if you are building a complicated program like a fighter jet target tracking system. But when you're writing a Web page that more or less stands by itself, being forced to dot all the i's and cross all the t's can be an annoying hindrance. After all, since almost all the variables are going to be strings and you're just gluing them together, what's the point of declaring types?
I don't think it is worth getting religious over which is the better
approach. For one thing, as discussed in the chapter "Sites that are really databases" this
is the easy part of building a relational database-backed Web
site. You've developed your data model, defined your transactions, and
designed your user interface. You're engaged in an almost mechanical
translation process. For another, if you were running AOLserver with
Oracle as the back-end database, you could have the best of both worlds
by writing simple Tcl procedures that called PL/SQL functions. We would
touch up the definition bbd_fetch_msg so that it was designed as a
PL/SQL function, which can return a value, rather than as a
procedure, which is called for effect. Then instead of
htp.print we'd simply RETURN the string. We could interface
it to the Web with a five-line AOLserver Tcl function:
# grab the input and set it to Tcl local variable MSG_ID set_form_variables # get an open database connection from AOLserver set db [ns_db gethandle] # grab one row from the database. Note that we're using the # Oracle dummy table DUAL because we're only interested in the # function value and not in any information from actual tables. set selection [ns_db 1row $db "select bbd_fetch_msg('$msg_id') as moby_string from dual"] # Since we told the ns_db API call that we only expected # one row back, it put the row directly into the SELECTION # variable and we don't have to call ns_db getrow set moby_string [ns_set get selection moby_string] # we call the AOLserver API call ns_return to # say "status code 200; MIME type is text/html" # and then send out the page ns_return 200 text/html $moby_string
 Application servers for Web publishing are generally systems that let
you write database-backed Web pages in Java. The key selling points of
these systems, which sell for as much as $35,000 per CPU, are increased
reliability, performance, and speed of development.
Application servers for Web publishing are generally systems that let
you write database-backed Web pages in Java. The key selling points of
these systems, which sell for as much as $35,000 per CPU, are increased
reliability, performance, and speed of development.
An application server reduces Web site speed and reliability.
PC Week tested Netscape Application Server and Sapphire/Web on June 22, 1998 and found that they weren't able to support more than 10 simultaneous users on a $200,000 8-CPU Sun SPARC/Solaris E4000 server. Not only did the products crash frequently but sometimes in such innovative ways that they had to reboot the whole computer (something done once every 30 to 90 days on a typical Unix server).
 Application servers encourage publishers to write Java code to
non-standard specifications. If you really want to build a Web site in
Java, use the Java Servlet standard so that you can run the same code under
AOLserver, Apache, Microsoft IIS, Netscape Enterprise, Sun Java Server,
etc.
Application servers encourage publishers to write Java code to
non-standard specifications. If you really want to build a Web site in
Java, use the Java Servlet standard so that you can run the same code under
AOLserver, Apache, Microsoft IIS, Netscape Enterprise, Sun Java Server,
etc.
 Because compiling Java is so difficult, application servers out of
necessity usually enforce a hard separation between people who do design
(build templates) and those who write programs to query the database
(write and compile Java programs). Generally, people can only argue
about things that they understand. Thus, a bunch of business executives
will approve a $1 billion nuclear power plant without any debate but
argue for hours about whether the company should spend $500 on a party.
They've all thrown parties before so they have an idea that maybe paper
cups can be purchased for less than $2.75 per 100. But none of them has
any personal experience purchasing cooling towers.
Because compiling Java is so difficult, application servers out of
necessity usually enforce a hard separation between people who do design
(build templates) and those who write programs to query the database
(write and compile Java programs). Generally, people can only argue
about things that they understand. Thus, a bunch of business executives
will approve a $1 billion nuclear power plant without any debate but
argue for hours about whether the company should spend $500 on a party.
They've all thrown parties before so they have an idea that maybe paper
cups can be purchased for less than $2.75 per 100. But none of them has
any personal experience purchasing cooling towers.
Analogously, if you show a super-hairy transactional Web service to a bunch of folks in positions of power at a big company, they aren't going to say "I think you would get better linguistics performance if you kept a denormalized copy of the data in the Unix file system and indexed it with PLS". Nor are they likely to opine that "You should probably upgrade to Solaris 2.6 because Sun rewrote the TCP stack to better handle 100+ simultaneous threads." Neither will they look at your SQL queries and say "You could clean this up by using the Oracle tree extensions; look up CONNECT BY in the manual."
What they will say is, "I think that page should be a lighter shade of mauve". In an application server-backed site, this can be done by a graphic designer editing a template and the Java programmer need never be aware of the change.
Do you need to pay $35,000 per CPU to get this kind of separation of "business logic" from presentation? No. You can download AOLserver for free and send your staff the following:
Similarly, if you've got Windows NT you can just use Active Server Pages with a similar directive to the developers: Put the SQL queries in a COM object and call it at the top of an ASP page; then reference the values returned within the HTML. Again, you save $35,000 per CPU and both AOLserver and Active Server Pages have much cleaner templating syntax than the application server products.To: Web Developers I want you to put all the SQL queries into Tcl functions that get loaded at server start-up time. The graphic designers are to build ADP pages that call a Tcl procedure which will set a bunch of local variables with values from the database. They are then to stick <%=$variable_name=> in the ADP page wherever they want one of the variables to appear. Alternatively, write .tcl scripts that implement the business logic and, after stuffing a bunch of local vars, call ns_adp_parse to drag in the ADP created by the graphic designer.
Furthermore, if there are parts of your Web site that don't have elaborate presentation, e.g., admin pages, you can just have the programmers code them up using standard AOLserver .tcl or .adp style (where the queries are mixed in with HTML).
Finally, you can use the Web standards to separate design from presentation. With the 4.x browsers, it is possible to pack a surprising amount of design into a cascading style sheet. If your graphic designers are satisfied with this level of power, your dynamic pages can pump out rat-simple HTML.
From my own experience, some kind of templating discipline is useful on about 25 percent of the pages in a typical transactional site. Which 25 percent? The pages that are viewed by the public (and hence get extensively designed and redesigned) and also require at least a screen or two of procedural language statements or SQL. Certainly templating is merely an annoyance when building admin pages, which are almost always plain text. Maybe that's why I find application servers so annoying; there are usually a roughly equal number of admin and user pages on the sites that I build.
Note: For a more detailed discussion of application servers, see http://www.photo.net/wtr/application-servers.html.
 Let's try to generally categorize the tools that are available. This
may sound a little familiar if you've recently read the options and axes
for evaluating server-side scripting languages and environments that I
set forth in "Sites That Are Really
Programs". However, there are some new twists to consider when
an RDBMS is in the background.
Let's try to generally categorize the tools that are available. This
may sound a little familiar if you've recently read the options and axes
for evaluating server-side scripting languages and environments that I
set forth in "Sites That Are Really
Programs". However, there are some new twists to consider when
an RDBMS is in the background.
Before selecting a tool, you must decide how much portability you need. For example, the PL/SQL script above will work only with the Oracle RDBMS. The AOLserver Tcl scripts above would work with any RDBMS if SQL were truly a standard. However, Oracle handles datetime arithmetic and storage in a non-standard way. So if you wanted to move an AOLserver Tcl application to Informix or some other product that uses ANSI-standard datetime syntax, you'd most likely have to edit any script that used datetime columns. If you were using Java Servlets and JDBC, in theory you could code in pure ANSI SQL and the JDBC driver would translate it into Oracle SQL.
Why not always use the tools that give the most portability? Because portability involves abstraction and layers. It may be more difficult to develop and debug portable code. For example, my friend Jin built some Web-based hospital information systems for a company that wants to be able to sell to hospitals with all kinds of different database management systems. So he coded it in Java/JDBC and the Sun JavaWebServer. Though he was already an experienced Java programmer, he found that it took him ten times longer to write something portable in this environment than it does to write AOLserver Tcl that is Oracle-specific. I'd rather write ten times as many applications and be stuck with Oracle than labor over portable applications that will probably have to be redesigned in a year anyway.
Speaking of labor, you have to look around realistically at the programming and sysadmin resources available for your project. Some tools are clearly designed for MIS departments with 3-year development schedules and 20-programmer teams. If you have two programmers and a three-month schedule, you might not even have enough resources to read the manuals and install the tool. If you are willing to bite the bullet, you might eventually find that these tools help you build complex applications with some client-side software. If you aren't willing to bite the bullet, the other end of this spectrum is populated by "litely augmented HTML for idiots" systems. These are the most annoying Web tools because the developers invariably leave out things that you desperately need and, because their litely augmented HTML isn't a general-purpose programming language, you can't build what you need yourself.
 All of the sites that I build these days are done with AOLserver, which
has been tested at more than 20,000 production sites since May 1995
(when it was called "NaviServer"). I have personally used AOLserver for
more than 100 popular RDBMS-backed services (together they are responding
to about 400 requests/second as I'm writing this sentence). AOLserver
provides the following mechanisms for generating dynamic pages:
All of the sites that I build these days are done with AOLserver, which
has been tested at more than 20,000 production sites since May 1995
(when it was called "NaviServer"). I have personally used AOLserver for
more than 100 popular RDBMS-backed services (together they are responding
to about 400 requests/second as I'm writing this sentence). AOLserver
provides the following mechanisms for generating dynamic pages:
I personally have never needed to use the C API and don't really want to run the attendant risk that an error in my little program will crash the entire Aolserver. The AOL folks swear that their thousands of novice internal developers find the gentle-slope programming of ADPs vastly more useful than the .tcl pages. I personally prefer the .tcl pages for most of my applications. My text editor (Emacs) has a convenient mode for editing Tcl but I'd have to write one for editing ADP pages. I don't really like the software development cycle of "sourced at startup" Tcl but I use it for applications like my comment server where I want db-backed URLs that look like "/com/philg/foobar.html" ("philg" and "foobar.html" are actually arguments to a procedure). These are very useful when you want a site to be dynamic and yet indexed by search engines that turn their back on "CGI-like" URLs. I've used the filter system to check cookie headers for authorization information and grope around in the RDBMS before instructing AOLserver to proceed either with serving a static page or with serving a login page.
You can build manageable complex systems in AOLserver by building a large library of Tcl procedures that are called by ADP or .tcl pages. If that isn't sufficient, you can write additional C modules and load them in at run-time.
AOLserver has its shortcomings, the first of which is that there is no support for sessions or session variables. This makes it more painful to implement things like shopping carts or areas in which users must authenticate themselves. Since I've always had an RDBMS in the background, I've never really wanted to have my Web server manage session state. I just use a few lines of Tcl code to read and write IDs in magic cookies.
The second shortcoming of AOLserver is that, though it started life as a commercial product (NaviServer), the current development focus is internal AOL consumption. This is good because it means you can be absolutely sure that the software works; it is the cornerstone of AOL's effort to convert their 11 million-user service to standard Web protocols. This is bad because it means that AOL is only investing in things that are useful for that conversion effort. Thus there aren't any new versions for Windows NT. I've found the AOLserver development team to be much more responsive to bug reports than any of the other vendors on which I rely. However, they've gone out of the handholding business. If you want support, you'll have to get it for free from the developer's mailing list or purchase it from a third-party (coincidentally, my own company is an authorized AOLserver support provider: http://www.arsdigita.com/aolserver-support.html).
You can test out AOLserver right now by visiting www.aol.com, one of the world's most heavily accessed Web sites. Virtually the entire site consists of dynamically evaluated ADP pages.

Ex Apache semper aliquid novi"Out of Apache, there is always something new."
-- Pliny the Hacker, Historia Digitalis, II, viii, 42, c. AD 77
The folks who wrote Apache weren't particularly interested in or experienced with relational database management systems. However, they gave away their source code and hence people who were RDBMS wizards have given us a constant stream of modules that, taken together, provide virtually all of the AOLserver goodies. By cobbling together code from modules.apache.org, a publisher can have a server that
Personally, I don't use Apache. I have a big library of AOLserver code that works reliably. I don't want to look at someone else's C code unless I absolutely have to.
 Active Server Pages (ASP) are a "gentle slope" Web scripting system. An
HTML document is a legal ASP page. By adding a few special characters,
you can escape into Visual Basic, JavaScript, or other languages such as
Perl (via plug-ins). If you edit an ASP page, you can test the new
version simply by reloading it from a browser. You don't have to
compile it or manually reload it into Internet Information Server (IIS).
Microsoft claims that IIS does "automatic database connection pooling".
You ought to be able to use almost any RDBMS with ASP and all the
communication is done via ODBC (see below) so that you won't have to
change your code too much to move from Solid to Sybase, for example.
Active Server Pages (ASP) are a "gentle slope" Web scripting system. An
HTML document is a legal ASP page. By adding a few special characters,
you can escape into Visual Basic, JavaScript, or other languages such as
Perl (via plug-ins). If you edit an ASP page, you can test the new
version simply by reloading it from a browser. You don't have to
compile it or manually reload it into Internet Information Server (IIS).
Microsoft claims that IIS does "automatic database connection pooling".
You ought to be able to use almost any RDBMS with ASP and all the
communication is done via ODBC (see below) so that you won't have to
change your code too much to move from Solid to Sybase, for example.
ASPs can invoke more or less any of the services of a Windows NT box via Microsoft's proprietary COM, DCOM, and ActiveX systems. The downside of all of this is that you're stuck with NT forever and won't be able to port to a Unix system if your service outgrows NT. Microsoft maintains some reasonably clear pages on ASP at http://www.microsoft.com/iis/.
 You can build a working Web site in AOLserver, Apache, or IIS/ASP. If
you read an advertisement for what sounds like a superior product,
ignore it. However superior this new product is, be sure that it will
probably be a mistake to switch. Once you build up a library of software
and expertise in Tool X, you're better off ignoring Tools Y and Z for at
least a few years. You know all of the bugs and pitfalls of Tool X. All
you know about Tool Y and Z is how great the hype sounds. Being out of
date is unfashionable, but so is having a down Web server, which is what
most of the leading edgers will have.
You can build a working Web site in AOLserver, Apache, or IIS/ASP. If
you read an advertisement for what sounds like a superior product,
ignore it. However superior this new product is, be sure that it will
probably be a mistake to switch. Once you build up a library of software
and expertise in Tool X, you're better off ignoring Tools Y and Z for at
least a few years. You know all of the bugs and pitfalls of Tool X. All
you know about Tool Y and Z is how great the hype sounds. Being out of
date is unfashionable, but so is having a down Web server, which is what
most of the leading edgers will have.
How much can it cost you to be out of date? Amazon.com has a market capitalization of $5.75 billion (August 10, 1998). They built their site with compiled C CGI scripts connecting to a relational database. You could not pick a tool with a less convenient development cycle. You could not pick a tool with lower performance (forking CGI then opening a connection to the RDBMS). They worked around the slow development cycle by hiring very talented programmers. They worked around the inefficiencies of CGI by purchasing massive Unix boxes ten times larger than necessary. Wasteful? Sure. But insignificant compared to the value of the company that they built by focusing on the application and not fighting bugs in some award-winning Web connectivity tool programmed by idiots and tested by no one.
 Netscape
is unique in that they offer a full selection of the worst
ideas in server-side Web programming. In May of 1997, I looked at
Netscape's server products and plans and wrote the following to a
friend:
Netscape
is unique in that they offer a full selection of the worst
ideas in server-side Web programming. In May of 1997, I looked at
Netscape's server products and plans and wrote the following to a
friend:
"Netscape would be out of the server tools business tomorrow if Microsoft ported IIS/ASP to Unix and/or if NT were more reliable and easier to maintain remotely."Since then they've acquired Kiva and renamed it "Netscape Application Server". A friend of mine runs a Web server complex with 15 Unix boxes, multiple firewalls, multiple RDBMS installations, and dozens of Web sites containing custom software. His number one daily headache and source of unreliability? Netscape Application Server.
Nobody has anything bad to say about Allaire's Cold Fusion but I can't see that it offers any capabilities beyond what you get with Microsoft's ASP. History has not been kind to people who compete against the Microsoft monopoly, particularly those whose products aren't dramatically better.
I used to take delight in lampooning the ideas of the RDBMS vendors. But, since they never even learned enough about the Internet to understand why they were being ridiculed, it stopped being fun. The prevailing wisdom in Silicon Valley is that most companies have only one good idea. Microsoft's idea was to make desktop apps. They've made a reasonably good suite of desktop apps and inflicted misery on the world with virtually everything else they've brought to market (most of which started out as some other company's product, e.g., SQL Server was Sybase, Internet Explorer was NCSA Mosaic, DOS was Tim Paterson's 86-DOS). Netscape's idea was to make a browser. They made a great browser and pathetic server-side stuff. The RDBMS vendors' idea was to copy the System R relational database developed by IBM's San Jose research lab. They all built great copies of IBM's RDBMS server and implementations of IBM's SQL language. Generally everything else they build is shockingly bad, from documentation to development tools to administration tools.
 Now that everything is connected, maybe you don't want to talk to your
RDBMS through your Web server. You may want to use standard
spreadsheet-like tools. There may even be a place for, dare I admit it,
junkware/middleware. First a little context.
Now that everything is connected, maybe you don't want to talk to your
RDBMS through your Web server. You may want to use standard
spreadsheet-like tools. There may even be a place for, dare I admit it,
junkware/middleware. First a little context.
An RDBMS-backed Web site is updated by thousands of users "out there" and a handful of people "back here." The users "out there" participate in a small number of structured transactions, for each of which it is practical to write a series of Web forms. The people "back here" have less predictable requirements. They might need to fix a typo in a magazine title stored in the database, for example, or delete a bunch of half-completed records because the forms-processing code wasn't as good about checking for errors as it should have been.
Every RDBMS-backed Web site should have a set of admin pages. These provide convenient access for the webmasters when they want to do things like purge stale threads from discussion groups. But unless you are clairvoyant and can anticipate webmaster needs two years from now or you want to spend the rest of your life writing admin pages that only a couple of coworkers will see, it is probably worth coming up with a way for webmasters to maintain the data in the RDBMS without your help.
 Both spreadsheet-like database editors and the applications generated
by "easy forms" systems connect directly to the RDBMS from a
PC or a Macintosh. This probably means that you'll need additional user
licenses for your RDBMS, one for each programmer or Web content
maintainer. In the bad old days, if you were using a forms building
package supplied by, say, Oracle then the applications generated would
get compiled with the Oracle C library and would connect directly to
Oracle. These applications wouldn't work with any other brand of
database management system. If you'd bought any third-party software
packages, they'd also talk directly to Oracle using Oracle
protocols. Suppose you installed a huge data entry system, then decided
that you'd like the same operators to be able to work with another
division's relational database. You typed the foreign division
server's IP address and port numbers into your configuration files and
tried to connect. Oops. It seems that the other division had chosen
Sybase. It would have cost you hundreds of thousands of dollars to port
your forms specifications over to some product that would generate
applications compiled with the Sybase C library.
Both spreadsheet-like database editors and the applications generated
by "easy forms" systems connect directly to the RDBMS from a
PC or a Macintosh. This probably means that you'll need additional user
licenses for your RDBMS, one for each programmer or Web content
maintainer. In the bad old days, if you were using a forms building
package supplied by, say, Oracle then the applications generated would
get compiled with the Oracle C library and would connect directly to
Oracle. These applications wouldn't work with any other brand of
database management system. If you'd bought any third-party software
packages, they'd also talk directly to Oracle using Oracle
protocols. Suppose you installed a huge data entry system, then decided
that you'd like the same operators to be able to work with another
division's relational database. You typed the foreign division
server's IP address and port numbers into your configuration files and
tried to connect. Oops. It seems that the other division had chosen
Sybase. It would have cost you hundreds of thousands of dollars to port
your forms specifications over to some product that would generate
applications compiled with the Sybase C library.
 From your perspective, Oracle and Sybase were interchangeable. Clients
put SQL in; clients get data out. Why should you have to care about
differences in their C libraries? Well, Microsoft had the same thought
about five years ago and came up with an abstraction barrier
between application code and databases called ODBC. Well-defined
abstraction barriers have been the most powerful means of controlling
software complexity ever since the 1950s. An abstraction barrier
isolates different levels and portions of a software system. In a
programming language like Lisp, you don't have to know how lists are
represented. The language itself presents an abstraction barrier of
public functions for creating lists and then extracting their
elements. The details are hidden and the language implementers are
therefore free to change the implementation in future releases because
there is no way for you to depend on the details. Very badly engineered
products, like DOS or Windows, have poorly defined abstraction
barriers. That means that almost every useful application program
written for DOS or Windows depends intimately on the details of those
operating systems. It means more work for Microsoft programmers because
they can't clean up the guts of the system, but paradoxically a monopoly
software supplier can make more money if its products are badly
engineered in this way. If every program a user has bought requires
specific internal structures in your operating system, there isn't too
much danger of the user switching operating systems.
From your perspective, Oracle and Sybase were interchangeable. Clients
put SQL in; clients get data out. Why should you have to care about
differences in their C libraries? Well, Microsoft had the same thought
about five years ago and came up with an abstraction barrier
between application code and databases called ODBC. Well-defined
abstraction barriers have been the most powerful means of controlling
software complexity ever since the 1950s. An abstraction barrier
isolates different levels and portions of a software system. In a
programming language like Lisp, you don't have to know how lists are
represented. The language itself presents an abstraction barrier of
public functions for creating lists and then extracting their
elements. The details are hidden and the language implementers are
therefore free to change the implementation in future releases because
there is no way for you to depend on the details. Very badly engineered
products, like DOS or Windows, have poorly defined abstraction
barriers. That means that almost every useful application program
written for DOS or Windows depends intimately on the details of those
operating systems. It means more work for Microsoft programmers because
they can't clean up the guts of the system, but paradoxically a monopoly
software supplier can make more money if its products are badly
engineered in this way. If every program a user has bought requires
specific internal structures in your operating system, there isn't too
much danger of the user switching operating systems.
Relational databases per se were engineered by IBM with a wonderful abstraction barrier: Structured Query Language (SQL). The whole raison d'être of SQL is that application programs shouldn't have to be aware of how the database management system is laying out records. In some ways, IBM did a great job. Just ask Oracle. They were able to take away most of the market from IBM. Even when Oracle was tiny, their customers knew that they could safely invest in developing SQL applications. After all, if Oracle tanked or the product didn't work, they could just switch over to an RDBMS from IBM.
Unfortunately, IBM didn't quite finish the job. They didn't say whether or not the database had to have a client/server architecture and run across a network. They didn't say exactly what sequence of bytes would constitute a request for a new connection. They didn't say how the bytes of the SQL should be shipped across or the data shipped back. They didn't say how a client would note that it only expected to receive one row back or how a client would say, "I don't want to read any more rows from that last SELECT." So the various vendors developed their own ways of doing these things and wrote libraries of functions that applications programmers could call when they wanted their COBOL, Fortran, or C program to access the database.
 It fell to Microsoft to lay down a standard abstraction barrier in
January 1993: Open Database Connectivity (ODBC). Then companies like
Intersolv (www.intersolv.com) released ODBC drivers. These are
programs that run on the same computer as the would-be database client,
usually a PC. When the telephone operator's forms application wants to
get some data, it doesn't connect directly to Oracle. Instead, it calls
the ODBC driver which makes the Oracle connection. In theory, switching
over to Sybase is as easy as installing the ODBC driver for
Sybase. Client programs have two options for issuing SQL through
ODBC. If the client program uses "ODBC SQL" then ODBC will
abstract away the minor but annoying differences in SQL syntax that have
crept into various products. If the client program wants to use a
special feature of a particular RDBMS like Oracle Context, then it can
ask ODBC to pass the SQL directly to the database management
system. Finally, ODBC supposedly allows access even to primitive
flat-file databases like FoxPro and dBASE.
It fell to Microsoft to lay down a standard abstraction barrier in
January 1993: Open Database Connectivity (ODBC). Then companies like
Intersolv (www.intersolv.com) released ODBC drivers. These are
programs that run on the same computer as the would-be database client,
usually a PC. When the telephone operator's forms application wants to
get some data, it doesn't connect directly to Oracle. Instead, it calls
the ODBC driver which makes the Oracle connection. In theory, switching
over to Sybase is as easy as installing the ODBC driver for
Sybase. Client programs have two options for issuing SQL through
ODBC. If the client program uses "ODBC SQL" then ODBC will
abstract away the minor but annoying differences in SQL syntax that have
crept into various products. If the client program wants to use a
special feature of a particular RDBMS like Oracle Context, then it can
ask ODBC to pass the SQL directly to the database management
system. Finally, ODBC supposedly allows access even to primitive
flat-file databases like FoxPro and dBASE.
You'd expect programs like Microsoft Access to be able to talk via ODBC to various and sundry databases. However, this flexibility has become so important that even vendors like Oracle and Informix have started to incorporate ODBC interfaces in their fancy client programs. Thus you can use an Oracle-brand client program to connect to an Informix or Sybase RDBMS server.
The point here is not that you need to rush out to set up all the database client development tools that they use at Citibank. Just keep in mind that your Web server doesn't have to be your only RDBMS client.